
随笔分类
对象
Redis并没有直接使用上述数据结构来显示键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象,每种对象都至少使用一种我们前面所介绍的数据结构
通过这五种不同类型的对象,Redis可以在执行命令之前,根据对象的类型来判断给定类型的对象是否能够执行给定的命令.
使用对象的另一个好处便是,可以根据具体的使用场景来为对象设置不同的数据结构,最大的优化对象在不同场景下的使用效率.
除此之外,Redis的对象系统实现了基于引用计数的内存回收机制,当程序不再使用某个对象时,该对象对应的内存便会被自动释放;另外,Redis还基于引用技术实现了对象共享机制,这一机制可以在适当的条件下,通过让多个数据库键共享同一个对象来节约内存
最后,Redis的对象带有访问时间记录信息,该信息可以用于计算数据库键的空转时间,在服务器启用了maxmemory功能的情况下,空转时长较大的那些键可能会优先被服务器删除.
类型与编码
Redis使用对象来表示数据库中的键和值,即每当我们往数据库新建一个键值对时,至少会创建两个对象:键对象和值对象

typedef struct redisObject {
// 记录了对象的类型,对于redis数据库而言,键总是一个字符串对象,而值可以是其他的对象
unsigned type:4;
// 编码
unsigned encoding:2;
// 指向底层实现数据结构的指针
void *ptr;
...
// 引用计数
int refcount;
// 记录对象最后一次被命令程序访问的时间
unsigned lru;
}正因为此特性(type),当我们称呼一个数据库键为"字符串键"时,我们指的是:这个数据库键所对应的值为字符串对象. 列表键、哈希键等同理
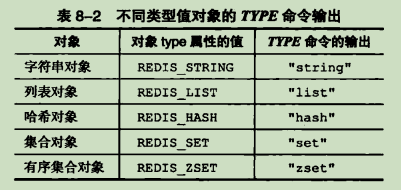
TYPE命令的实现方式也与此类似,当我们对一个数据库键执行 TYPE命令时,返回的结果是该数据库键对应的值对象的类型,而非数据键对象的类型
不同类型值对象的 TYPE命令输出
lake:0>set name "liangye"
"OK"
lake:0>type name
"string"
lake:0>RPUSH numbers 1 2 3 4 5 6
"6"
lake:0>type numbers
"list"对象的 ptr指针指向对象的底层实现数据结构,而这些数据结构由对象的 encoding属性决定
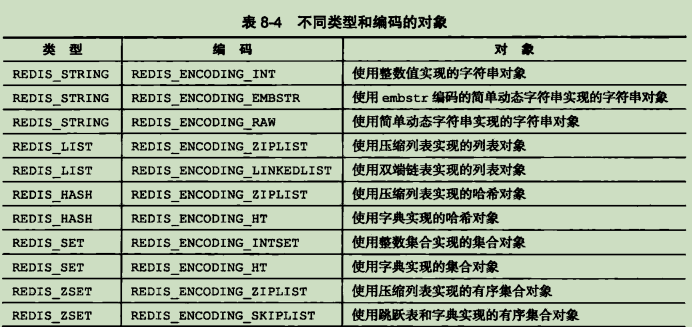
encoding属性记录了对象所使用的的编码,即这个对象选择了哪种数据结构作为底层实现,这个属性的值可以是下列表示的其中一个:

每种类型的对象都至少使用了两种不同的编码:
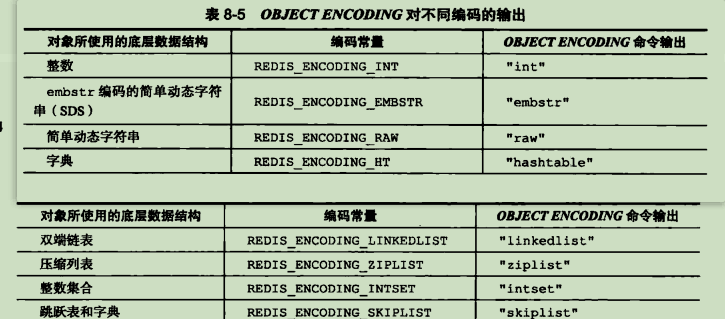
可以使用 OBJECT ENCODING命令查看一个数据库键的值对象的编码:
通过 encoding属性来设定对象所使用的编码,而不是为特定对象关联一种编码,这极大地提升了 Redis的灵活性和效率,即 Redis可以根据不同的使用场景来为对象设置不同的编码,从而优化对象在某一场景下的效率.
举个例子,在列表对象包含的元素比较少时,Redis使用 压缩列表作为列表键的底层实现:
- 因为列表键比双端列表更节省内存,并且在元素数量比较少时,在内存中以连续块保存的压缩列表比起双端链表可以更快地被载入内存
- 而当列表对象包含的对象组件多起来时,使用压缩列表来保存元素的优势逐渐消失,Redis会使用功能更加强大、更适合保存大量元素的双端链表作为列表键的底层实现
其它不同的对象实际上也会通过不同的编码来作类似的优化.
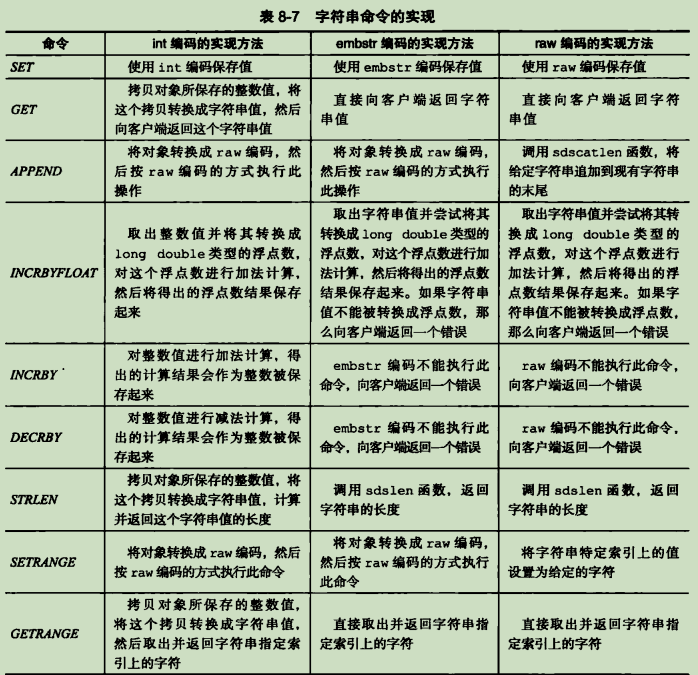
字符串对象
字符串的编码可以是 int、raw或者 embstr
《Redis设计与实现》中说明 raw与 emstr的分割线是32字节实测并不准确,
实测为 44字节,于此记录一下
-
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long类型来表示,那么字符串对象便会将这个整数值保存在其结构里的 ptr属性里面(将 void* 保存为 long),并且将字符串的编码设置为
int -
如果一个字符串对象保存的是一个字符串值,且这个字符串值的长度大于34字节,那么字符串对象将会使用一个简单动态字符串(SDS)来保存这个字符串的值,并且将对象的编码设置为
rawlake:0>strlen name "45" lake:0>object encoding name "raw" -
如果一个字符串的对象保存的是一个字符串值,并且这个字符串的长度小于等于 34字节,那么字符串对象将使用
embstr编码的方式来保存这个字符串值lake:0>strlen sky "44" lake:0>object encoding sky "embstr" # 可见,分割线却是变为了44字节embstr是专门用于保存短字符串的一种优化编码方式,这种编码和 raw编码一样,都使用了 redisObject 和 sdshdr结构来表示字符串对象,而 raw编码会调用两次内存分配函数分别创建redisObject 和 sdshdr结构,而empstr仅调用一次内存分配函数来分配一块连续的空间,空间中一次包含了 redisobject和 sdshdr两个结构
embstr编码的对象在执行命令时和 raw编码的效果一致,但是使用 embstr编码来保存短字符串值有以下好处:
- embstr编码创建字符串对象只需一次内存重分配的调用
- 释放 embstr编码的字符串对象只需调用一次内存释放函数,而 raw编码的需调用两次
- embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,这种编码的字符串对象能更好地利用缓存带来的优势

int编码的字符串对象和 emstr编码的字符串对象在条件满足的情况下,会被转换为 raw编码的字符串对象.
lake:0>set number 123
"OK"
lake:0>APPEND number "is a good number"
"19"
lake:0>OBJECT ENCODING number
"raw"
lake:0>TYPE number
"string"且 redis并没有为 emstr编码的字符串编写任何相应的修改程序(只有 int编码和 raw编码的有),因此,emstr编码的字符串对象是只读的,当对 emstr编码的字符串对象执行修改命令时,其实是现将 emstr编码的转为 raw编码的字符串对象,然后在进行相应修改.
lake:0>set name liangye
"OK"
lake:0>OBJECT ENCODING name
"embstr"
lake:0>APPEND name " is a good boy"
"21"
lake:0>OBJECT ENCODING name
"raw"
列表对象
列表对象的编码可以是 ziplist 或者 linkedlist
ziplist作为底层实现时,每一个压缩列表结点(entry)保存了一个列表元素.
linkedlist作为底层实现时,每个链表节点(node)保存了一个字符串对象,而每一个字符串对象保存了一个列表元素.
lake:0>RPUSH numbers 1 "two" 3
"3"
lake:0>TYPE numbers
"list"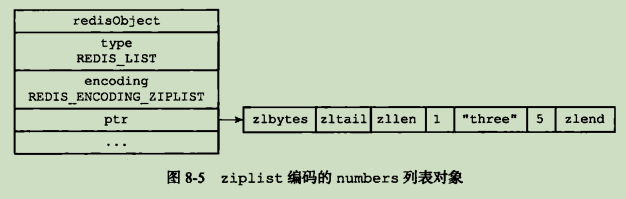
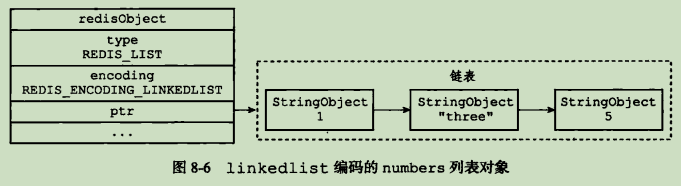
linkedlist编码的字符串对象在底层的双端链表结构中包含了多个字符串对象,这种嵌套字符串对象的行为在哈希对象、集合对象和有序集合对象中同样出现了,字符串对象时Redis五种类型的对象中唯一一个会被四种类型对象嵌套的对象.

编码转换
当列表对象可以同时满足以下两个条件时,列表对象使用 ziplist编码
- 列表对象保存的所有的元素的长度都小于64字节
- 列表对象保存的元素数目少于 512个;
- 若不满足以上两个条件便会去使用 linkedlist编码
列表命令的实现

哈希对象
哈希对象的编码可以是 ziplist 或者 hashtable
ziplist编码的哈希对象时,每当有新的键值对要加入哈希对象时,程序会将保存了键的压缩列表结点推入到压缩列表尾部,再将保存了值的压缩列表结点推入到压缩列表尾部
-
保存了同一键值对的两个节点总是
紧凑在一起,保存键的节点在前面,保存了值的节点在后面 -
先添加到哈希对象中的键值对会被推入压缩列表表头,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向

hashtable编码的哈希对象使用字典作为底层实现时,哈希对象中的每一个键值对都使用一个字典键值对来进行保存
- 字典中每个键都是字符串对象,保存了键值对的键
- 字典中每个值都是字符串对象,保存了键值对的值
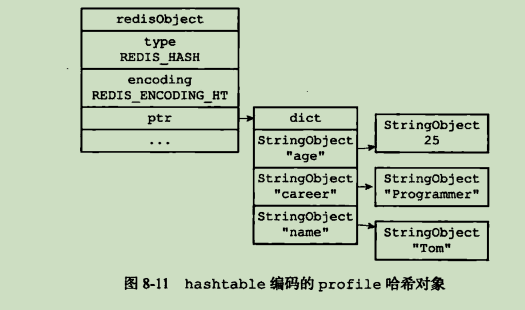
类型转换
当哈希对象可以同时满足一下两个条件时,哈希对象使用 ziplist编码
- 哈希对象保存的键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数目小于521个
- 若不能满足以上两个条件,哈希对象需要使用 hashtable编码,即可能会引起编码类型的转换.

集合对象
集合对象的编码可以是 intset或者 hashtable
intset编码的集合对象使用整数集合作为底层实现,集合对象中包含的所有元素都被保存在整数集合中
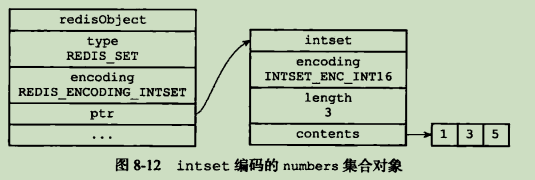
hashtable编码的集合对象使用字典作为底层实现,字典中的每一个键都是一个字符长对象,每个字符串对象保存的一个集合元素,字典的值全部被设置为 NULL

编码转换
当集合对象中元素满足以下两个条件时,对象使用 intset编码
- 集合对象中保存的所有元素都是整数值
- 集合对象中保存的元素数量少于 512个
- 不满足以上条件时便会使用 hashtable作为编码实现
命令实现

有序集合对象
有序集合的编码可以是 ziplist 或者 skiplist
ziplist编码的有序集合对象选择压缩列表作为底层实现,每个集合中的元素使用两个紧挨在一起的压缩列表结点来保存,第一个节点保存的是元素的成员(member),第二个节点保存的是元素的分值(score).
压缩列表内的集合元素按照分值进行从小到大的排序,分值较小的元素被放置在靠近表头的方向,分值较大的元素则会被放置在靠近表尾的方向.
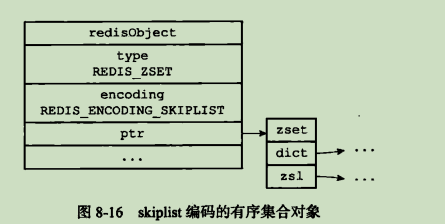
skiplist编码的有序集合对象是指 zset结构作为底层实现,一个 zset结构同时包含了一个字典和一个跳跃表.
typedef struct zset {
zskiplist *zsl;
dict *dict:
}zset结构中的 zsl跳跃表按分值从小到大保存了所有的集合对象,每个跳跃表节点都保存了一个集合元素:节点的 object属性保存了元素的成员,节点的 score属性保存了元素的分值;通过这个跳跃表,程序便可以对此有序集合进行范围操作,比如 ZRANK、ZRANGE等命令都是基于跳跃表 API进行实现的.
除此之外,zset的 dict字典为有序集合创建了一个从成员到值的映射,字典中的每一个键值对都保存了一个集合元素:键保存了集合元素成员,值则保存了元素对应分值;通过此字典,便可以仅花费 O(1)的复杂度来查找指定成员的分值;ZSCORE命令就是根据这一特性实现的,而很多其他有序集合命令都用到了这个特性.
有序集合的每个元素的成员都是一个字符串对象,而元素的分值都是一个 double类型的浮点数. 值得一提的便是,虽然 zset结构同时使用跳跃表和字典来保存有序集合对象,但是这两种数据结构都会通过指针来共享相同元素的成员和分值,即这也就保证了即使是使用了两种数据结构来保存集合元素也不会出现任何的重复成员及其分值,不会因此而造成内存的浪费.

为什么有序集合要同时使用跳跃表的字典作为底层实现?

编码转换
当集合对象中元素同时满足以下两个条件时,对象使用 ziplist编码
- 集合对象中保存的所有元素成员长度都小于64字节
- 集合对象中保存的元素数量少于 128个
- 不满足以上条件时便会使用 skiplist作为编码实现
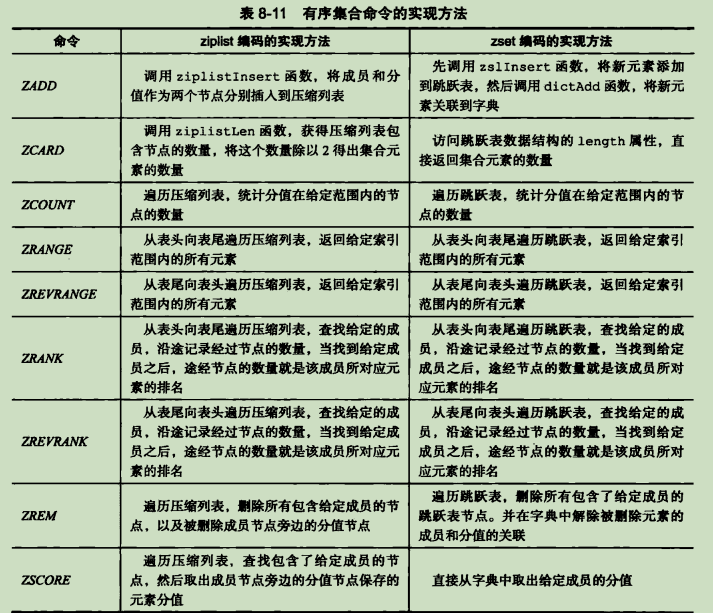
有序集合命令的实现
类型检查与命令多态
Redis用于操作键的命令基本上可以分为两种,其中一种命令可以对任何类型的键执行(类型多态),比如说 DEL、EXPIRE、RENAME、TYPE、OBJECT等命令,而另一种类型只能对特定类型的键执行.
- SET、GET、APPEND、STRLEN等命令只能对字符串键执行
- HDEL、HSET、HGET、HLEN等命令只能对哈希键执行
- RPUSH、LPOP、LINSERT、LLEN等命令只能对列表键执行
- SADD、SPOP、SINSERT、SCARD等命令只能对集合键执行
- ZADD、ZCARD、ZRANK、ZSCORE等命令只能对有序集合键执行.
为了避免类型错误的发生,在执行类型特定命令之前,Redis会先去检查输入键的类型是否正确,然后再去决定是否执行给定的命令.
类型检查是通过 redisObject结构的 type属性来实现的,当类型检查发现类型不匹配时,服务器端会返回类型错误的信息.
多态
Redis除了会根据键对象的类型来判断键是否能够执行指定命令,还会根据值对象的编码方式,选择正确的命令实现代码作为执行命令
这其实就是面向对象特性中多态(编码多态)的体现,当一个键的值对象有多种实现方式,只要保证键的类型检查过的去,便无需忧虑其值对象具体的执行此命令的方式,即命令均能正常执行.
内存回收
C语言并不具备自动内存回收的特性,所以 Redis在自己的对象构建了一个基于引用计数技术实现的内存回收机制,通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行自动内存回收
每个对象的引用计数信息由 redisObject结构的 refcount属性记录
对象的引用计数信息会随着对象的使用状态而不断变化
- 在创建一个对象时,引用计数的值为1
- 当对象被一个新程序使用时,引用计数的值加一
- 当对象不再被一个程序使用时,引用计数的值减一
- 当对象的引用计数的值为 0时,对象所占用的内存就会被释放.

但对象的引用计数属性除了用于内存回收外,其还有着对象共享的作用
在Redis中,可以让多个键的值共享同一个对象,只要让键的值指针指向共享对象,且将共享对象的引用计数加一即可
对象共享机制对于节省内存非常有帮助,数据库中保存的相同的值对象越多,对象共享机制就能节省越多的内存.
目前来说,Redis会在初始化服务器时,创建一万个字符串对象,这些对象包含了从0到 9999的所有整数值,当服务器需要使用 0 - 9999的字符串对象时,服务器便是去使用这些共享对象,而非去创建新的对象.

空转时长
last-recently-used
redisObject结构中包含的最后一个属性为 lru属性,该属性记录了对象最后一次被命令程序访问的时间.
OBJECT IDLETIME 命令可以打印出给定键的空转时长(当前时间减去此对象上一次被访问的时间),需要注意一点的便是,该命令的实现是特殊的,即执行此命令的时候并不会更新值对象的 lru属性.
如果服务器打开了 maxmemory选项,且服务器内存回收的算法为 volatile-lru或者 allkeys-lru,那么当服务器占用的内存数大于 maxmemory中设置的上限值时,空转时长比较大的那些键会优先被服务器删除,以来回收内存.













