
随笔分类
Trie Tree
实际上,如果在没有遍历底部叶子节点的情况下,我们就能够在树的顶部弄清楚 key是否存在的话,这就很 nice!
前缀树
别名:prefix tree、digital search tree
Trie Tree是比 B+Tree更加古老的存在
对于 Trie Tree,它并没有保存我们树中节点里的 key的完整拷贝,保存的会是 key的 digit (key中的某些原子子集,如:一个字节或者一个 bit之类的)
基本思想:对 key进行分解,基于一层层来表示 digit,对于重复出现的 key或者 digit,只需在每层保存一次即可
将 key隐式地存储在路径中
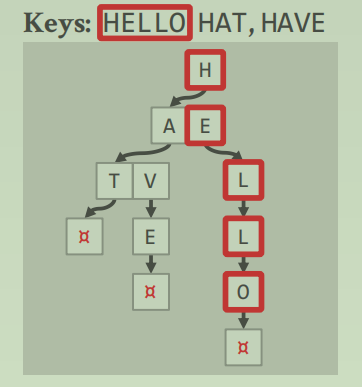
Trie Tree的底部实际上是和 B+Tree是一致的,它可以是一个 record id,也可以是 tuple本身
properties
Trie的形状取决于 key的分布以及它们的长度,即对于 Trie Tree,其本身时确定形状的数据结构
-
不管插入 key的顺序如何,最终都会得到相同的物理数据结构
这是区别于 B+Tree,B+Tree的形状实际上是和我们
拆分与合并的方式息息相关 -
对于 Trie Tree,所有操作都有 O(K)的时间复杂度,而 B+Tree的时间复杂度为 O(log(N))
K,取决于我们查找的 key的长度
对于点查询而言,Tries的速度要比 B+Tree快很多
但对于循序扫描的话,Tries需要进行回溯,相比之下,B+Tree可以沿着叶子节点来进行查找,二者之间的差距就很大了
compact
前缀压缩,本身就是对 key的一种简化了,还可以再进行进一步的压缩吗?
答案是,可以的,且有两种方式:
看个例子:
对于 span为 1的 digit:
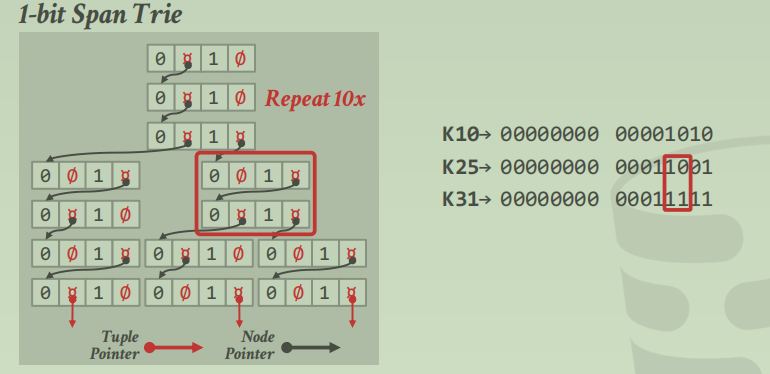
level
水平压缩
对于上述例子,实际上我们并不需要使用额外的空间来表示 0、1,可以根据 偏移量来判断标志即可
且通过偏移量,也能快速跳到我们想要的那个 offset值处
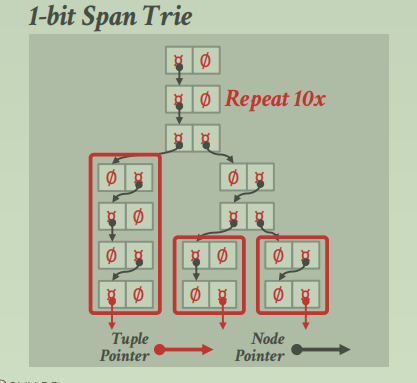
virtual
垂直压缩
如果某一层的 digit对于的 key是唯一的话,那就可以来删除指向下面的 trie节点,直接指向该 key的 tuple指针即可
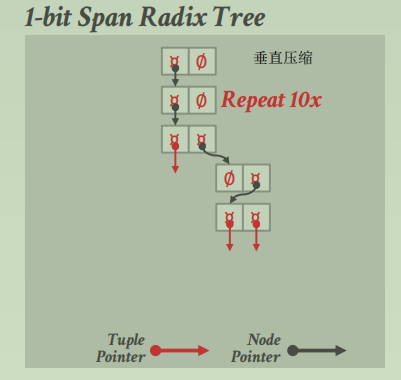
这其实就是 Radix Tree (一种特殊的 Trie Tree,一种变体)
当你进行垂直压缩时,以此来移除下面没有其它明显区分路径的所有节点 (移除无用分支路线,即真实情况是看似多条路线,但只有一条存储了明确 key的路线)
inverted index
倒排索引
有时候也叫,全文搜索索引
基本思想:倒排索引会将 word映射到英语或者其它自然语言的词汇上 (并不是处理器中的字节序列),它会将单词映射到包含这些单词的 record上,接着,这就允许它根据这个索引来进行查找04
- 如:请帮我找到包含该关键字的所有 record
summary
实际上除了 B+Tree,hash index,trie-Tree,redix-tree,还有着许多类型的索引
它们可以来做点查询以及范围查询以外的东西













