
随笔分类
IO多路复用
实际上就是使用操作系统的事件通知 API注册一些非阻塞的套接字,以确定是否有任何的 socket已有数据可供读写了
BIO & NIO
前述
Socket有两种工作模式:BIO与 NIO
BIO与 NIO的区别到底是什么?
这段时间,自己也在学习 IO相关知识,经过些许思考,我感觉是 阻塞
怎么来理解阻塞呢?
说实话,我感觉这挺难讲清楚的...
从 Java层面上讲吧,我们实际上是生活在 甜蜜罐里的,怎么说的,因为前辈们已经将 IO的实际调用都封装在 Api里了,这简化了我们对 IO的使用,但也正因为这样,我们对 IO的理解也挺浅层的
这里挺熟悉的,感觉就像是回到了学 jvm那段时期,为啥要去学 jvm?jvm自动内存管理的确挺香的,可不深入进行了解,能行吗?
开始正题
怎么来理解阻塞?
个人理解:执行某 ops时,若是该 ops所需的某些资源 (必要条件)尚未具备 / 发生,是否需要等待该事件的发生,还是直接返回?我认为这就是 Bio与 Nio的最大区别
Socket缓冲区
以 Server和 Client高层来进行理解吧
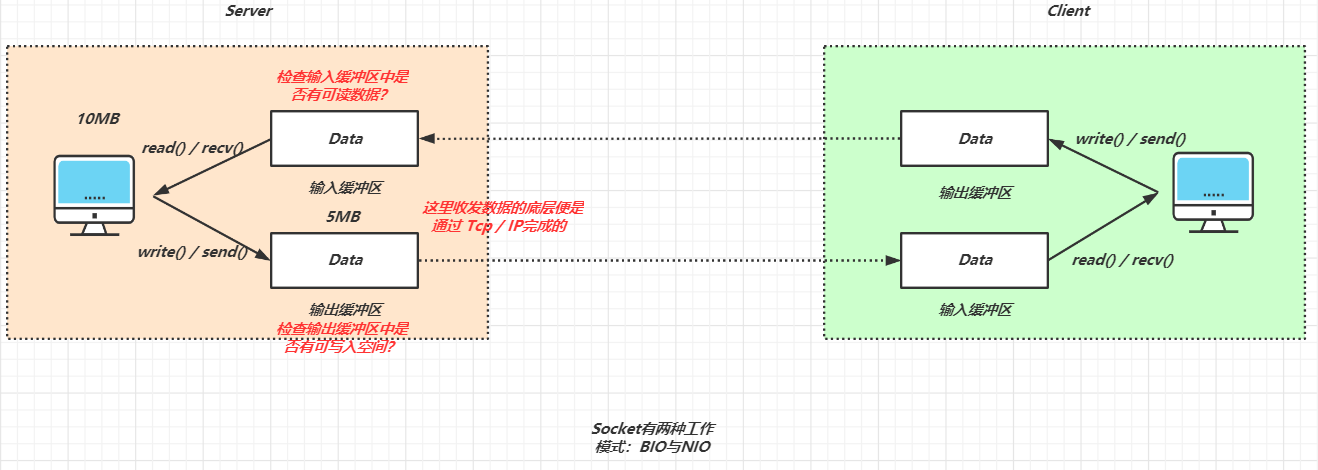
每个 Socket被创建后,都会被分配两个缓冲区:输入缓冲区和输出缓冲区
当我们调用 read() / recv()时,并不是直接从网络中去获取数据,而是从输入缓冲区中获取数据;同理,调用 write() / send()时,并不是立即向网络中传输数据,而是现将数据写入到输出缓冲区,再由底层协议 (Tcp / Ip)将数据从缓冲区去发送到目标机器
-
这也是为什么我们在发送数据时,要去使用
flush()的原因! - 输出缓冲区的数据何时才会真正发送到网络中?这个时间点实际上是不确定的!-
缓冲区中数据达到上限时,会触发数据真正的写出
-
显式调用 flush时,也会触发数据的写出
但 flush调用多了,缓冲区性能其实也就下降了,,
-
-
一旦将数据写入到缓冲区,函数就可以成功返回了,不管它们有没有到达目标机器,也不管它们合适被发送到网络,这些都是 Tcp协议负责的事情
summary
- IO缓冲区在每个 Socket中单独存在,在创建 Socket时便会自动生成
- 即使关闭了套接字,输出缓存区中的数据也会被继续传送,这是 Tcp协议会去负责保证的
- 关闭套接字,将会丢失输入缓冲区中的数据
为什么要有 IO缓冲区呢?
这个问题,个人觉得还是比较值得探讨的,虽然目前还是理解不深,但也来说说下自己的看法吧!
-
一方面,IO缓冲区能够去解耦高层 App (Srever、Client)与发送数据之间的强关联
如果没有 IO缓冲区,那么用户程序发送数据时,就以对应的线程来说,Java线程将会阻塞直到系统层面将数据发送完毕后才能够返回
而有了 Socket缓冲区后呢?
用户线程只需要将数据拷贝后 Socket的输出缓冲区,便可以返回了,剩下的事情便是 Tcp / Ip负责的事情了
注:Socket缓冲区实际上是在内核空间的!
Socket socket = new Socket("localhost", 8080)触发了
系统调用,Socket属于系统资源,在内核层面创建好 Socket,为其分配好对应的 IO缓冲区,并去设置该 Socket连接的主机地址及其对应的端口号,这便是在 os层面上会去干的事,而在 Java层面就简化封装成了这段代码,因此说咋们 Java程序员真的很幸福了... -
另一方面,缓冲区本身缓冲机制,提高了程序性能
这个好理解,如果每次调用函数时只写入少量数据,就基于 Tcp协议进行数据的网络传输,实际上这是
低效的因此,将数据缓冲起来,数据达到一定上限时,再去发送可以来提高程序性能
但这也带来了一定的问题
即
黏包与半包问题,这类问题也是网络编程中常见的,若是仅使用 Bio与 Nio的话,我们最常用的方式就是基于分隔符来进行数据的分割操作了,但这性能不高好在 Netty很好地为我们提供了这类问题的解决思路,这里就不提及了...
以上就是我对 Socket缓冲区的理解,感觉还是有诸多不足之处,日后再进行补充吧
基于 Socket讲解阻塞
还是上面那张图
实际上读写操作和程序中定义的 ByteBuffer与 Socket对于的缓冲区大小是密切相关的,因此需要理清这其中的关系
read操作:
read操作实际上对应了两个阶段:数据就绪阶段、数据拷贝阶段
高层面调用 read相关函数时,触发系统调用,cpu从用户态切换至内核态,此时去检查 socket对应的 输入缓冲区是否有数据,有数据则进行数据的读取,若没有数据,则会阻塞程序直至输入缓冲区中有数据可读时,将数据读入后 (实际上是 拷贝到用户空间),程序才能向下运行
这期间,进程都是出于 Blocked状态,直到数据拷贝到用户态!
以上便是 Bio下的读操作
Nio下的读操作呢?
区别于 Bio,cpu从用户态切换至内核态后,无需去等待数据的就绪阶段,直接对输入缓冲区进行读取,读取完毕后直接返回即可,对应函数返回的便是此次操作实际读取的数据字节数
可以看到,若是对应 IO缓冲区中没有数据,进程并不会阻塞等待数据的到来
write操作
同样也是会触发系统调用,cpu从用户态切换至内核态,进行 IO缓冲区数据的写入操作
这里来假设一种场景:实际要写入的数据 10Mb,而当前输出缓冲区可用空间 5Mb,Bio与 Nio会做出什么操作呢?
Bio:先进行一次写入操作,然后阻塞等待输出缓冲区有可写入空间,直至数据全部写入到缓冲区中去,返回到用户态,程序才能继续往下执行对应的逻辑
Nio:进行非阻塞的写,由场景来说,此次 write操作只会写入 5Mb,然后函数就进行了返回,此时写操作并未全部完成,因此对于 Nio下的写,我们回去根据 ByteBuffer的写指针来去判断当前写入数据的量,决定是否需要进行多次写操作
反思
前段时间面试时,因为项目中有用到 WebSocket来搭建聊天室,webRtc实现语音交流,因此,被问到了一些相关的问题,大致总结一下:
- 如何去保证在沟通时来保证消息的顺序性,如:A发送先,B发送后,如何保证接收时 A、B的顺序性
- 从底层上讲述,WebSocket如何来实现,讲细节
说实话,一开始我听到这两个问题时,的确挺懵的,因为这些都是自己的知识盲区
但随着这阵子的学习网络编程,逐渐意识到第一个问题确实不难,可以从 Socket实现将其,联系缓冲区,以及数据发送基于 Tcp协议,Tcp协议中数据的顺序性、不丢失,拥塞控制,拥塞避免等等,我认为当前面试官想要考察的就是这一块知识点,可惜了当时自己对 Socket尚未了解,不过也看出了对于有些知识点,还是需要联系实际开发应用的,不然这会是纯粹的知识点,并没有做到真正的落地!
对于第二个问题,结合上述其实也可以来讲述一些,不过应该不彻底,这就先留着吧,mark,待日后补充...
变态
用户堆栈与内核堆栈
个进程都会有自己的堆栈,内核在创建进程时,为其创建进程描述符的同时,也会为进程创建自己的堆栈;一个进程有两个堆栈,用户堆栈 和 内核堆栈;
用户堆栈的空间指向用户空间地址,内核堆栈的空间指向内核地址空间
当进程在用户态运行时,cpu中的堆栈指针寄存器指向的是用户堆栈空间,使用的是用户堆栈;进程运行在内核态时,cpu中的堆栈指针寄存器指向的是内核堆栈空间,使用的是内核堆栈
切换
当进程由于 中断或者系统调用从用户态切换至系统态时,进程所使用的堆栈也需要从用户堆栈切换至内核堆栈
即此时对应的就是一些进程上下文环境 (Process Context)的保存
cpu中存在着许多寄存器,如:代码地址、行号、堆栈指针地址、操作数等,进程在切换时,这些数据都是需要被保存的,保存到 进程描述符中去
设置完 Process Context后,cpu中寄存器状态信息要进行设置,否则无法进行状态的切换:代码地址从用户代码变为了内核代码,堆栈地址从用户堆栈变为内核堆栈等等;
当执行完内核代码相关逻辑后,需要根据进程描述符中保存的数据进行 上下文恢复,之后 cpu装配能够寄存器就恢复为未执行切换之前的状态,之后便继续来执行对应的用户代码相关逻辑即可













