
随笔分类
解读 RecvBytebufAllocator
在上一次对消息处理进行解读时,我们发现始终有 RecvBytebufAllocator影响着我们对代码逻辑的阅读
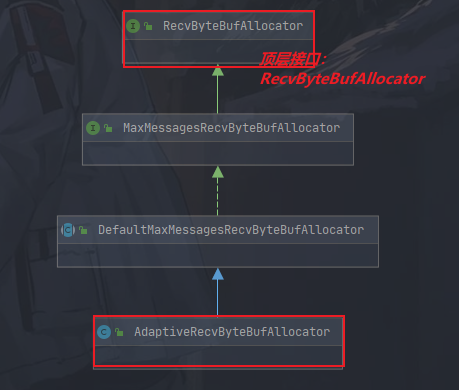
RecvByteBufAllocator
这是 AdaptiveRecvByteBufAllocator的顶层接口,我们来逐层进行剖析
public interface RecvByteBufAllocator {
/**
* Creates a new handle. The handle provides the actual operations and keeps the internal information which is
* required for predicting an optimal buffer capacity.
*/
// 创建一个 handler, 这个 handler对象的作用就是预测下一次分配多大的 byteBuf对象, 大小需合理
Handle newHandle();
/**
* @deprecated Use {@link ExtendedHandle}.
*/
@Deprecated
interface Handle {
/**
* Creates a new receive buffer whose capacity is probably large enough to read all inbound data and small
* enough not to waste its space.
*/
// 分配 ByteBuf缓冲区对象的接口, 参数很重要! - handler这一层提供预测分配的 size
// 参数:alloc - 真正去进行内存分配的对象
ByteBuf allocate(ByteBufAllocator alloc);
/**
* Similar to {@link #allocate(ByteBufAllocator)} except that it does not allocate anything but just tells the
* capacity.
*/
// 获取 ByteBuf Size预测值
int guess();
/**
* Reset any counters that have accumulated and recommend how many messages/bytes should be read for the next
* read loop.
* <p>
* This may be used by {@link #continueReading()} to determine if the read operation should complete.
* </p>
* This is only ever a hint and may be ignored by the implementation.
* @param config The channel configuration which may impact this object's behavior.
*/
void reset(ChannelConfig config);
/**
* Increment the number of messages that have been read for the current read loop.
* @param numMessages The amount to increment by.
*/
// 自增已读消息数量
void incMessagesRead(int numMessages);
/**
* Set the bytes that have been read for the last read operation.
* This may be used to increment the number of bytes that have been read.
* @param bytes The number of bytes from the previous read operation. This may be negative if an read error
* occurs. If a negative value is seen it is expected to be return on the next call to
* {@link #lastBytesRead()}. A negative value will signal a termination condition enforced externally
* to this class and is not required to be enforced in {@link #continueReading()}.
*/
// 设置最后一次从 Channel中读取的数据量大小, 这里指的就是 ByteBuf Size
void lastBytesRead(int bytes);
/**
* Get the amount of bytes for the previous read operation.
* @return The amount of bytes for the previous read operation.
*/
// 获取最后一次从 Channel中读取的数据量大小
int lastBytesRead();
/**
* Set how many bytes the read operation will (or did) attempt to read.
* @param bytes How many bytes the read operation will (or did) attempt to read.
*/
// 设置即将想要读取的数据量, 或者已经读取过的数据量
void attemptedBytesRead(int bytes);
/**
* Get how many bytes the read operation will (or did) attempt to read.
* @return How many bytes the read operation will (or did) attempt to read.
*/
// 获取即将想要读取的数据量, 或者已经读取过的数据量
int attemptedBytesRead();
/**
* Determine if the current read loop should continue.
* @return {@code true} if the read loop should continue reading. {@code false} if the read loop is complete.
*/
// 判断是否需要继续读取数据 - 对应 "读循环"(NioMessageUnsafe.read() | NioByteUnsafe.read())
boolean continueReading();
/**
* The read has completed.
*/
// 本次读循环完毕
void readComplete();
}
...MaxMessageRecvByteBufAllocator
// 对 RecvByteBufAllocator的初步增强
public interface MaxMessagesRecvByteBufAllocator extends RecvByteBufAllocator {
/**
* Returns the maximum number of messages to read per read loop.
* a {@link ChannelInboundHandler#channelRead(ChannelHandlerContext, Object) channelRead()} event.
* If this value is greater than 1, an event loop might attempt to read multiple times to procure multiple messages.
*/
// 获取每次读循环操作最多能够去读取的消息数量 - 每到 Channel内拉一次数据称为一个消息
int maxMessagesPerRead();
/**
* Sets the maximum number of messages to read per read loop.
* If this value is greater than 1, an event loop might attempt to read multiple times to procure multiple messages.
*/
// 设置每次读循环最多能够去读取的消息数量
MaxMessagesRecvByteBufAllocator maxMessagesPerRead(int maxMessagesPerRead);
}接着来看看 MaxMessageRecvByteBufAllocator的实现类
DefaultMaxMessageRecvByteBufAllocator
public abstract class DefaultMaxMessagesRecvByteBufAllocator implements MaxMessagesRecvByteBufAllocator {
// 表示每次读循环最多能够去读取的消息数量
private volatile int maxMessagesPerRead;
private volatile boolean respectMaybeMoreData = true;
...
// 对 ExtendedHandle的增强
// 实际上我们也不难发现, 外层类只是给内层类提供参数来使用的而已, 本身并没有去做其它事 - 可以理解为是对内层内部类的一种封装 ?
public abstract class MaxMessageHandle implements ExtendedHandle {
// channel中 config
private ChannelConfig config;
// 表示每次读循环最多能够去读取的数据量
private int maxMessagePerRead;
// 已经读取的消息数量
private int totalMessages;
// 已经读取的消息 size总大小
private int totalBytesRead;
// 预估要去读的字节数量, 或者已经读取过的数据量
private int attemptedBytesRead;
// 表示最后一次读取的数据量
private int lastBytesRead;
// true
private final boolean respectMaybeMoreData = DefaultMaxMessagesRecvByteBufAllocator.this.respectMaybeMoreData;
private final UncheckedBooleanSupplier defaultMaybeMoreSupplier = new UncheckedBooleanSupplier() {
@Override
public boolean get() {
// 对比预估读取的数据量是否等于最后一次读取的数据量
// true - 说明 Channel内可能还剩余有数据尚未读取完, 需要继续进行读取
// false: a.评估的数据量产生的 ByteBuf > 剩余数据量 b.channel关闭了, lastBytesRead == -1
// false - 表示的都是不需要进行读取了
return attemptedBytesRead == lastBytesRead;
}
};
/**
* Only {@link ChannelConfig#getMaxMessagesPerRead()} is used.
*/
// 重置当前 handler
@Override
public void reset(ChannelConfig config) {
this.config = config;
// 重置 读循环最大可读取的数据量 - 默认情况下是 16 - 对于服务端和客户端一样
maxMessagePerRead = maxMessagesPerRead();
// 重置统计字段
totalMessages = totalBytesRead = 0;
}
// 参数:alloc - 真正去进行内存分配的分配器
@Override
public ByteBuf allocate(ByteBufAllocator alloc) {
// 参数 - guess() 返回的即是预测的 ByteBuf Size, 即根据读循环过程中的上下文评估的一个适合读大小的 ByteBuf SIZE
// alloc.ioBuffer(size) - 根据预估 ByteBuf大小去创建出 ByteBuf对象
return alloc.ioBuffer(guess());
}
@Override
public final void incMessagesRead(int amt) {
totalMessages += amt;
}
@Override
public void lastBytesRead(int bytes) {
// 记录上一次读取的数据
lastBytesRead = bytes;
if (bytes > 0) {
totalBytesRead += bytes; // 更新总已读的数据量大小
}
}
@Override
public final int lastBytesRead() {
return lastBytesRead;
}
// 核心 - 这也是外层控制读循环和核心方法
@Override
public boolean continueReading() {
return continueReading(defaultMaybeMoreSupplier);
}
@Override
public boolean continueReading(UncheckedBooleanSupplier maybeMoreDataSupplier) {
// 只有四个条件全部都成立时, 读循环才会继续进行
// 条件一:config.isAutoRead() 默认是 true
// 条件二:maybeMoreDataSupplier.get() 判断上一次读取数据量是否等于此次预估的要去读取的数据量大小以此来判断是否还需要进行数据的读取
// 条件三:totalMessages < maxMessagePerRead:一次 unsafe.read()最多能从 channel中读取 16次数据, 不能超过 16次
// 条件四:totalBytesRead > 0:
// 客户端:通常情况下都会成立, 在读循环中只要读取到了数据, 便会去将读取到的数据量累计到 totalBytesRead中去
// 但若累计读取的数据量过多了, 超过了 Integer.MAX_VALUE, 则会是 false - 由此可以看出, 一次客户端发送的数据最多只能是 Integer.MAX_VALUE
// 服务端:由 unsafe.read()可知, 并没有去更新 totalBytesRead, 因此这里会是 false - 即对于服务端读循环而言, 循环实际上只会进行一次
return config.isAutoRead() &&
(!respectMaybeMoreData || maybeMoreDataSupplier.get()) &&
totalMessages < maxMessagePerRead &&
totalBytesRead > 0;
}
@Override
public void readComplete() {
}
@Override
public int attemptedBytesRead() {
return attemptedBytesRead;
}
@Override
public void attemptedBytesRead(int bytes) {
attemptedBytesRead = bytes;
}
// 返回累计读取的数据量
protected final int totalBytesRead() {
return totalBytesRead < 0 ? Integer.MAX_VALUE : totalBytesRead;
}
}
}实际上到这里,我们也发现了外层类实际上就是来给内层类提供参数使用的,或者说是基于外层类来对内层类来进行初始化
在此类中,显然我们更为关注的方式的 continueReading(),此方法控制着我们读循环是否继续,继续的话需要同时满足四个条件,详细可看代码
接着,来到我们最为关注的类 AdaptiveRecvByteBufAllocator
AdaptiveRecvByteBufAllocator
/**
* The {@link RecvByteBufAllocator} that automatically increases and
* decreases the predicted buffer size on feed back.
* <p>
* It gradually increases the expected number of readable bytes if the previous
* read fully filled the allocated buffer. It gradually decreases the expected
* number of readable bytes if the read operation was not able to fill a certain
* amount of the allocated buffer two times consecutively. Otherwise, it keeps
* returning the same prediction.
*/
public class AdaptiveRecvByteBufAllocator extends DefaultMaxMessagesRecvByteBufAllocator {
// 默认最小值
static final int DEFAULT_MINIMUM = 64;
// Use an initial value that is bigger than the common MTU of 1500
static final int DEFAULT_INITIAL = 2048; // 默认初始值
static final int DEFAULT_MAXIMUM = 65536; // 默认最大值
// 索引增量 - 4
private static final int INDEX_INCREMENT = 4;
// 索引减量 - 1
private static final int INDEX_DECREMENT = 1;
// size table - 里面存储着不同大小的 size, 实际上是供给 guess()方法使用
// guess()会上下文来 size table中取出一个合适的 size, 然后去 alloc()中去为 ByteBuf分配内存, 即创建
private static final int[] SIZE_TABLE;
// 初始代码块
static {
List<Integer> sizeTable = new ArrayList<Integer>();
// 初始化 sizeTable < 512时, 增量 16
for (int i = 16; i < 512; i += 16) {
sizeTable.add(i);
}
// Suppress a warning since i becomes negative when an integer overflow happens
// 大于 512时, 每次自增一倍
// 由这里我们也可以看出 size最大其实就是 Integer.MAX_VALUE
for (int i = 512; i > 0; i <<= 1) { // lgtm[java/constant-comparison]
sizeTable.add(i);
}
// 接着, 便是对 size_table进行初始化
SIZE_TABLE = new int[sizeTable.size()];
for (int i = 0; i < SIZE_TABLE.length; i ++) {
SIZE_TABLE[i] = sizeTable.get(i);
}
}
/**
* @deprecated There is state for {@link #maxMessagesPerRead()} which is typically based upon channel type.
*/
@Deprecated
public static final AdaptiveRecvByteBufAllocator DEFAULT = new AdaptiveRecvByteBufAllocator();
// 二分查找算法, 在 size table中查找与当前值最接近的 size对应的下标(下标在数组中的对应的值可能小于或大于 size, 但一定是最接近的)
private static int getSizeTableIndex(final int size) {
for (int low = 0, high = SIZE_TABLE.length - 1;;) {
if (high < low) {
return low;
}
if (high == low) {
return high;
}
int mid = low + high >>> 1;
int a = SIZE_TABLE[mid];
int b = SIZE_TABLE[mid + 1];
if (size > b) {
low = mid + 1;
} else if (size < a) {
high = mid - 1;
} else if (size == a) {
return mid;
} else {
return mid + 1;
}
}
}
// 可以理解为:外层类的属性其实就是来对内层类 HandleImpl进行初始化
// 这里即对 MaxMessageHandle的增强
private final class HandleImpl extends MaxMessageHandle {
private final int minIndex;
private final int maxIndex;
private int index;
// 表示下一次分配的 byteBuf的容量大小
private int nextReceiveBufferSize;
private boolean decreaseNow;
HandleImpl(int minIndex, int maxIndex, int initial) {
this.minIndex = minIndex;
this.maxIndex = maxIndex;
// 计算出 2048在 SIZE_TABLE中对应下标
index = getSizeTableIndex(initial);
// 可以看出, nextReceiveBufferSize初始值便是 2048
nextReceiveBufferSize = SIZE_TABLE[index];
}
@Override
public void lastBytesRead(int bytes) {
// If we read as much as we asked for we should check if we need to ramp up the size of our next guess.
// This helps adjust more quickly when large amounts of data is pending and can avoid going back to
// the selector to check for more data. Going back to the selector can add significant latency for large
// data transfers.
// 条件成立:说明读取的数据量与评估的数据量一致, 说明 Channel内可能数据未读取完, 还需要继续读取
if (bytes == attemptedBytesRead()) {
// record()方法想要去更新 nextReceiveBufferSize大小
// 因为前面评估的量被读满了, 可能 Channel中存在很多需要被读取的数据, 因此可能需要去创建更大容量的 ByteBuf
// 参数:本次实际读取到的数据量
record(bytes);
}
super.lastBytesRead(bytes);
}
@Override
public int guess() {
return nextReceiveBufferSize;
}
// 参数:本次实际读取到的数据量
private void record(int actualReadBytes) {
// 举个例子:
// 假设 SIZE_TABLE[index] = 2048 -> SIZE_TABLE[index] = 1024
// 如果第二次读取的数据量 <= 1024, 说明 channel缓冲区数据不是很多, 可能就不需要去创建那么大的 ByteBuf了 - 注意是第二次!
if (actualReadBytes <= SIZE_TABLE[max(0, index - INDEX_DECREMENT)]) {
// 第一次这里会是 false
// 第二次再来到这会是 true
if (decreaseNow) {
// 将 index自减, 但需确保 SIZE_TABLE[index - 1] >= minimum
index = max(index - INDEX_DECREMENT, minIndex);
// 设置下一次要去创建的 ByteBuf大小 - 可以看到, 减少了
nextReceiveBufferSize = SIZE_TABLE[index];
// 由此, 可以看出只有上层分支满足两次时, 才会真正去更新 nextReceiveBufferSize - 个人理解:这是为了减少误判率
decreaseNow = false;
} else {
// 第一次会来到这设置为 true
decreaseNow = true;
}
} else if (actualReadBytes >= nextReceiveBufferSize) { // 增大逻辑 - 真实读取的数据量是大于预估读取的 - 可能 Channel中存在很多数据要去读取
// 将 index自增, 但也许确保 SIZE_TABLE[index] <= maximum
index = min(index + INDEX_INCREMENT, maxIndex);
// // 设置下一次要去创建的 ByteBuf大小 - 可以看到, 增大了
nextReceiveBufferSize = SIZE_TABLE[index];
decreaseNow = false; // 这里可以理解为是对误差的纠正
}
}
@Override
public void readComplete() {
// 这里的参数实际上在循环中累计去读取的数据量
// 这里实际上也是 ByteBuf size伸缩性的体现
// 评估 Channel上的数据量, 来去设置一个更大的 ByteBuf size - 因此下一次 Channel再有数据过来时,
// 直接设置这个比较大的 size去创建 ByteBuf进行行数据的读取
record(totalBytesRead());
}
}
private final int minIndex;
private final int maxIndex;
private final int initial;
/**
* Creates a new predictor with the default parameters. With the default
* parameters, the expected buffer size starts from {@code 1024}, does not
* go down below {@code 64}, and does not go up above {@code 65536}.
*/
public AdaptiveRecvByteBufAllocator() {
// 参数一:64
// 参数二:2048
// 参数三:65536
this(DEFAULT_MINIMUM, DEFAULT_INITIAL, DEFAULT_MAXIMUM);
}
/**
* Creates a new predictor with the specified parameters.
*
* @param minimum the inclusive lower bound of the expected buffer size
* @param initial the initial buffer size when no feed back was received
* @param maximum the inclusive upper bound of the expected buffer size
*/
// 参数一:64
// 参数二:2048
// 参数三:65536
// 构造方法中主要对 minIndex、maxIndex、initial进行了赋值
public AdaptiveRecvByteBufAllocator(int minimum, int initial, int maximum) {
checkPositive(minimum, "minimum");
if (initial < minimum) {
throw new IllegalArgumentException("initial: " + initial);
}
if (maximum < initial) {
throw new IllegalArgumentException("maximum: " + maximum);
}
// 二分查找算法, 在 size table中查找与当前值最接近的 minimum对应的下标(下标在数组中的对应的值可能小于或大于 minimum, 但一定是最接近的)
int minIndex = getSizeTableIndex(minimum);
if (SIZE_TABLE[minIndex] < minimum) {
// 确保 SIZE_TABLE[minIndex] >= minimum
this.minIndex = minIndex + 1;
} else {
// 即, 找到合适的下标了 maxIndex
this.minIndex = minIndex;
}
// 二分查找算法, 在 size table中查找与当前值最接近的 maximum对应的下标(下标在数组中的对应的值可能小于或大于 maximum, 但一定是最接近的)
int maxIndex = getSizeTableIndex(maximum);
if (SIZE_TABLE[maxIndex] > maximum) {
// 确保 SIZE_TABLE[maxIndex] <= maximum - 确保不能超出阈值嘛
this.maxIndex = maxIndex - 1;
} else {
// 即找到合适的 maxIndex
this.maxIndex = maxIndex;
}
// 初始值:2048
this.initial = initial;
}
@SuppressWarnings("deprecation")
// 创建出 HandleImpl
@Override
public Handle newHandle() {
// 这里的参数其实就是 AdaptiveRecvByteBufAllocator构造中所去设置的值
// 参数一:64在 SIZE_TABLE中对应下标
// 参数二:65536在 SIZE_TABLE中对应下标
// 参数三:2048
return new HandleImpl(minIndex, maxIndex, initial);
}
@Override
public AdaptiveRecvByteBufAllocator respectMaybeMoreData(boolean respectMaybeMoreData) {
super.respectMaybeMoreData(respectMaybeMoreData);
return this;
}
}
这里需要关注的有 newHandle()方法,实际创建出的就是 HandleImpl实例,而 HandlerImpl是对 DefaultMaxMessagesRecvByteBufAllocator.MaxMessageHandle的扩展,而 MaxMessageHandle又是对 RecvByteBufAllocator.ExtendedHandle的扩展,而 ExtendedHandle本身又是对 RecvByteBufAllocator.Handle的扩展,可以看到,环环相扣,正如前面所示,一切都联系起来了
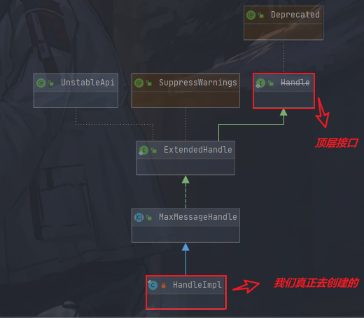
在此类中,存在着一个 int数组 SIZE_TABLE,此数组中存着的实际上就是不同尺寸大小的 Size,这些 Size将用于后续预估分配 ByteBuf内存大小时会来进行使用,即通过 guess()会来获取到下一次 ByteBuf对应的 Size
而在静态初始代码块中,我们可以看到里面存储的值:小于 512前,递增量 16,大于等于 512之后,对应的便是一倍增长,即对应 512,1204,,最大即为 Integer.MAX_VALUE,因此这里可以猜想出对于服务端一次所能读取的数据,实际上最多也就是 Integer.MAX_VALUE
显然,此时我们更加关注于第一次 guess()返回值是多少,返回的是 nextReceiveBufferSize,而其值在 HandleImpl初始代码块中就已经初始化了,即对应着的便是 nextReceiveBufferSize = SIZE_TABLE[index]
而 index对应的值其实就是在 SIZE_TABLE中最为接近 INITIAL的值,在此 Netty版本对应的便是 2048,因此,2048对应的便是 1024 < 1,so,第一次创建的 ByteBuf Size为 2048
其实再稍微看看,对于我们创建的 ByteBuf Size其实是有大小限制的,最小得大于等于 minIndex,最大也得小于等于 maxIndex,而二者的值实际上是根据 DEFAULT_MINIMUN、DEFAULT_MAXIMUM在 getSizeTableIndex()中基于 二分查找算法所计算出的,而其索引对应的真实值可能是大于或者小于 size的,但肯定是最为接近的
接着,接着在 HandleImpl中还有一个我认为是最为体现 ByteBuf弹性功能的一个方法 record(),此方法会根据本次实际读取到的数据量与上一次预测的 ByteBuf Size进行对比,动态实现对下一次要去创建的 ByteBuf Size进行调整,实际上就是为了提升系统性能的
至此,RecvByteBufAllocator解读完毕!
对 Unsafe.read()的些许补充
由上一篇对消息处理的解读,我们已经知道了 final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle()实际创建的就是 HandleImpl实例
这次以 NioByteUnsafe.read()再次进行解读!
@Override
public final void read() {
// 获取客户端 config
final ChannelConfig config = config();
if (shouldBreakReadReady(config)) {
clearReadPending();
return;
}
// 获取客户端 pipeine
final ChannelPipeline pipeline = pipeline();
// 获取缓冲区分配器 - 只要平台不是安卓的, 获取的缓冲区分配器就是池化内存管理的缓冲区分配器 PooledByteBufAllocator
final ByteBufAllocator allocator = config.getAllocator();
// RecvByteBufAllocator - 控制读循环, 以及预测下一次创建的 ByteBuf的大小
// 因此这里的 alloHandle实际上就是 HandleImpl实例
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
// 重置...
allocHandle.reset(config);
// 对 JDk层面的 ByteBuffer的增强接口实现
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
// 参数:池化内存管理的缓冲区分配器, 它才是真正去进行内存分配的主
// allocHandle 只是来预测下要去分配的内存大小
// 这块便是对 byteBuf分配内存 - 第一次分配的内存大小会是 2048
byteBuf = allocHandle.allocate(allocator);
// doReadBytes(byteBuf) - 读取当前 socket缓冲区数据到 byteBuf中去 - 返回真实从 SocketChannel读取的数据量
// lastBytesRead() - 更新缓存区预测分配器的 最后一次读取数据量...
allocHandle.lastBytesRead(doReadBytes(byteBuf));
// true:
// a.channel底层 socket读缓冲区已经读取完毕了, 没有数据可读了, 返回 0
// b.channel对端关闭了,会返回 -1
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
readPending = false;
}
break;
}
// 更新缓存区预测分配器 读取的消息数量
allocHandle.incMessagesRead(1);
readPending = false;
// 往客户端 Channel的 pipeline中传播 ChannelRead()事件, 感兴趣的 handler可以来做些业务处理
pipeline.fireChannelRead(byteBuf); // 由这不难看出, 每处理一次数据读取都会去广播 ChannelRead()事件
byteBuf = null;
} while (allocHandle.continueReading());
// 来到这, 说明消息已经读取完毕了
allocHandle.readComplete(); // 调用了 HandleImpl.readComplete()
// 往客户端 Channel的 pipeline中传播 ChannelReadComplete()事件
// 并且来设置客户端对应 SelectionKey感兴趣事件包含了 Read, 表示对应 selector需要继续帮当前 channel监听可读事件
pipeline.fireChannelReadComplete();
if (close) {
closeOnRead(pipeline);
}
} catch (Throwable t) {
handleReadException(pipeline, byteBuf, t, close, allocHandle);
} finally {
// Check if there is a readPending which was not processed yet.
// This could be for two reasons:
// * The user called Channel.read() or ChannelHandlerContext.read() in channelRead(...) method
// * The user called Channel.read() or ChannelHandlerContext.read() in channelReadComplete(...) method
//
// See https://github.com/netty/netty/issues/2254
if (!readPending && !config.isAutoRead()) {
removeReadOp();
}
}
}在 allocHandle.reset(config)中,这也是进入循环前调用的方法,这里做了什么?
// 重置当前 handler
@Override
public void reset(ChannelConfig config) {
this.config = config;
// 重置 读循环最大可读取的数据量 - 默认情况下是 16 - 对于服务端和客户端一样
maxMessagePerRead = maxMessagesPerRead();
// 重置统计字段
totalMessages = totalBytesRead = 0;
}实际上就是对 handle进行重置,这也就保证了每次进入读循环时的 handle是独立的,但这里 nextRecvBufferSize并未重置哦!
接着便是再读循环中创建了 ByteBuf,在 doReadBytes中进行了数据的读取,然后将该方法返回来的值也就是实际读取到的字节数作为参数去调用了 lastBytesRead()方法,该方法中又做了什么?
@Override
public void lastBytesRead(int bytes) {
// If we read as much as we asked for we should check if we need to ramp up the size of our next guess.
// This helps adjust more quickly when large amounts of data is pending and can avoid going back to
// the selector to check for more data. Going back to the selector can add significant latency for large
// data transfers.
// 条件成立:说明读取的数据量与评估的数据量一致, 说明 Channel内可能数据未读取完, 还需要继续读取
if (bytes == attemptedBytesRead()) {
// record()方法想要去更新 nextReceiveBufferSize大小
// 因为前面评估的量被读满了, 可能 Channel中存在很多需要被读取的数据, 因此可能需要去创建更大容量的 ByteBuf
// 参数:本次实际读取到的数据量
record(bytes);
}
super.lastBytesRead(bytes);
}可以看到,如果 Channel中可能还有未去读取的数据的话,其调用了 config(),由上可知,其就是去设置下一次要去创建的 ByteBuf的大小
之后,便是通过 allocHandle.continueReading()控制着读循环的进行
在出读循环后,去调用了 allocHandle.readComplete()
@Override
public void readComplete() {
// 这里的参数实际上在循环中累计去读取的数据量
// 这里实际上也是 ByteBuf size伸缩性的体现
// 评估 Channel上的数据量, 来去设置一个更大的 ByteBuf size - 因此下一次 Channel再有数据过来时,
// 直接设置这个比较大的 size去创建 ByteBuf进行行数据的读取
record(totalBytesRead());
}可以看到,这里调用了 record(),传递的参数其实就是此次读循环所读取到的全部字节数
这样的话,下一次客户端再来发送数据时,创建的将会是一个十分大的 ByteBuf,基于上一次所接收的数据量,说不定能耗时更少的接收次数实现数据的快速读取,本质上这也是对于系统性能的考虑













