
随笔分类
对内存申请的解读
调用 ByteBufAllocator.DEFAULT.buffer(),业务层面指定想要去获取的内存大小
@Override
public ByteBuf buffer(int initialCapacity) {
// 我们来考虑分配直接内存的情况
if (directByDefault) {
return directBuffer(initialCapacity);
}
return heapBuffer(initialCapacity);
}
// 参数:指定想要去分配的内存
@Override
public ByteBuf directBuffer(int initialCapacity) {
// 参数一:指定想要去分配的内存
// 参数二:允许分配的最大内存:Integer.MAX_VALUE
return directBuffer(initialCapacity, DEFAULT_MAX_CAPACITY);
}
// 参数一:指定想要去分配的内存
// 参数二:允许分配的最大内存:Integer.MAX_VALUE
@Override
public ByteBuf directBuffer(int initialCapacity, int maxCapacity) {
if (initialCapacity == 0 && maxCapacity == 0) {
return emptyBuf;
}
validate(initialCapacity, maxCapacity);
return newDirectBuffer(initialCapacity, maxCapacity);
}申请内存,最终都会来到 ByteBufAllocator,我们直接来考虑池化内存的分配,并且是对直接内存的分配,对应的便是 PooledByteBufAllocator.newDirectBuffer()
// 参数一:指定想要去分配的内存
// 参数二:允许分配的最大内存:Integer.MAX_VALUE
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 每个线程都会去 threadCache(PoolThreadLocalCache类型, 继承自FastThreadCache)中去获取线程相关的 PoolThreadCache(起到延迟释放 ByteBuf的作用)
// 这里便是去获取 | 创建线程独占的 PoolThreadCache, 并进行相应的初始化操作
// 每个 PoolThreadCache中会有两个区域:HeapArena、DirectArena
PoolThreadCache cache = threadCache.get();
// 获取分配给当前线程的 directArena区域, 后面会在这个区域进行内存的申请操作
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
// true
if (directArena != null) {
// 参数一:当前线程相关的 PoolThreadCache
// 参数二:指定想要去分配的内存容量
// 参数三:允许分配的最大内存:Integer.MAX_VALUE
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}可以看到,首先是去获取线程相关的 PoolThreadCache,对应的便是 threadCache.get()
获取线程相关的 PoolThreadCache
threadCache又是什么呢?
// threadCache非常类似于 ThreadLocal, 每个线程都可以到 threadCache中去获取与当前线程相关的 PoolThreadCache
private final PoolThreadLocalCache threadCache; final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {threadCache从继承体系图上可以看到,其继承 FastThreadLocal
这块先简单理解,threadCache非常类似于 ThreadLocal,每个线程都可以到 threadCache中去获取与当前线程相关的 PoolThreadCache
及对应 FastThreadLocal.get()
/**
* Returns the current value for the current thread
*/
@SuppressWarnings("unchecked")
public final V get() {
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.get();
Object v = threadLocalMap.indexedVariable(index);
if (v != InternalThreadLocalMap.UNSET) {
return (V) v;
}
// 我们来考虑这种情况
return initialize(threadLocalMap);
}
private V initialize(InternalThreadLocalMap threadLocalMap) {
V v = null;
try {
// 这里便去调用了重写后的方法(PoolThreadLocalCache.initialValue())
v = initialValue();
} catch (Exception e) {
PlatformDependent.throwException(e);
}
threadLocalMap.setIndexedVariable(index, v);
addToVariablesToRemove(threadLocalMap, this);
return v;
}最终 (我们考虑 threadCache未命中的情况),我们会来到 PoolThreadLocalCache中重写的 initialValue()
@Override
protected synchronized PoolThreadCache initialValue() {
// 获取使用率最低的 heap类型的 Arena
// 这里会返回 Arena内 "线程共享数"最低的 Arena
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
// 获取使用率最低的 direct类型的 Arena
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
final Thread current = Thread.currentThread();
// 条件一:true, 允许所有线程去使用 PoolThreadCache技术
// 条件二:true, NioEventLoop中线程是 FastThreadLocalThread类型(第一次往 NioEventLoop提交任务时会由 DefaultThreadFactory去创建线程)
if (useCacheForAllThreads || current instanceof FastThreadLocalThread) {
// 创建出与当前线程相关的 PoolThreadCache
// 参数一:allocator中线程共享数最少的 heap类型的 Arena
// 参数二:allocator中线程共享数最少的 direct类型的 Arena
// 参数三:表示 TinyMemoryRegionCache可以去存放的内存位置信息 - 512
// 参数四:表示 SmallMemoryRegionCache可以去存放的内存位置信息 - 256
// 参数五:表示 NormalMemoryRegionCache可以去存放的内存位置信息 - 64
// 参数六:32k, 表示 MemoryRegionCache允许缓存的最大内存规格:32k - 如, NormalMemoryCacheSize
// 参数七:8192
final PoolThreadCache cache = new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
if (DEFAULT_CACHE_TRIM_INTERVAL_MILLIS > 0) {
final EventExecutor executor = ThreadExecutorMap.currentExecutor();
if (executor != null) {
executor.scheduleAtFixedRate(trimTask, DEFAULT_CACHE_TRIM_INTERVAL_MILLIS,
DEFAULT_CACHE_TRIM_INTERVAL_MILLIS, TimeUnit.MILLISECONDS);
}
}
// 返回创建出来并初始化后的 PoolThreadCache
return cache;
}
// No caching so just use 0 as sizes.
return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0);
}由前述,我们知道,PooledByteBufAllocator中管理着两种类型的 Arena,即 heapArena、directArena
而在此便是去根据获取的一些元信息,去创建于当前线程相关的 PoolThreadCache 线程本地缓存
获取的元信息主要有:当前 Allocator内线程共享数最少的 heapArena、directArena;以及对应的三种规格的 MemoryRegionCache中能够去存放的内存位置信息等
我们主要关注的便是 directArena这块,先来看看是如何去获取 allocator内共享线程数最低的 Arena,对应的便是 leastUsedArena()方法的调用
// 这里会返回 Arena内 "线程共享数"最低的 Arena
private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) {
if (arenas == null || arenas.length == 0) {
return null;
}
PoolArena<T> minArena = arenas[0];
// 迭代 Arena
for (int i = 1; i < arenas.length; i++) {
PoolArena<T> arena = arenas[i];
// 找出 共享线程数最低的 Arena
if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) {
minArena = arena;
}
}
return minArena;
}这块其实就是去遍历并进行比较而已
接着,回到 PoolThreadCache的创建
// 创建出与当前线程相关的 PoolThreadCache
// 参数一:allocator中线程共享数最少的 heap类型的 Arena
// 参数二:allocator中线程共享数最少的 direct类型的 Arena
// 参数三:表示 TinyMemoryRegionCache可以去存放的内存位置信息 - 512
// 参数四:表示 SmallMemoryRegionCache可以去存放的内存位置信息 - 256
// 参数五:表示 NormalMemoryRegionCache可以去存放的内存位置信息 - 64
// 参数六:32k, 表示 MemoryRegionCache允许缓存的最大内存规格:32k - 如, NormalMemoryCacheSize
// 参数七:8192
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena,
int tinyCacheSize, int smallCacheSize, int normalCacheSize,
int maxCachedBufferCapacity, int freeSweepAllocationThreshold) {
checkPositiveOrZero(maxCachedBufferCapacity, "maxCachedBufferCapacity");
// 8192, 当使用 PoolThreadCache get 8192次之后, 会进行一次主动清理空闲内存的逻辑,
// 将缓存的内存位置信息归还给 PoolAllocator
this.freeSweepAllocationThreshold = freeSweepAllocationThreshold;
// 保存分配给当前线程的 Arena, 注:Arena是多线程共享的, 但是一个线程只会有一个指定的 heapArena、directArena
this.heapArena = heapArena;
this.directArena = directArena;
// 条件一般都会成立 - 线程本地缓存有着三种规格类型的 MemoryRegionCache数组:tiny、small、normal
if (directArena != null) {
// 类型:MemoryRegionCache, 里头存储的是 ByteBuf - createSubpageCaches
// 参数一:tinyCacheSize {512}
// 参数二:32, 对应着 32种规格
// 参数三:SizeClass.Tiny 类型
// 创建出长度为 32的 MemoryRegionCache数组, 并且数组中每一个元素都是 SubpageMemoryRegionCache类型
// 每一个 SubpageMemoryRegionCache都会有一个固定长度的 queue(org.jctools包下的)- 这里是 512
tinySubPageDirectCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
// 类型:MemoryRegionCache, 里头存储的是 ByteBuf - createSubpageCaches
// 参数一:smallCacheSize {256}
// 参数二:4, 对应着 4种规格
// 参数三:SizeClass.Small 类型
// 创建出长度为 4的 MemoryRegionCache数组, 并且数组中每一个元素都是 SubpageMemoryRegionCache类型
// 每一个 SubpageMemoryRegionCache都会有一个固定长度的 queue(org.jctools包下的)- 这里是 256
smallSubPageDirectCaches = createSubPageCaches(
smallCacheSize, directArena.numSmallSubpagePools, SizeClass.Small);
// 参数:8k
// 13 - 以 2为底, 8192为对数
// 这个值后面会使用到
numShiftsNormalDirect = log2(directArena.pageSize);
// 类型:MemoryRegionCache, 里头存储的是 ByteBuf - 这里调用的方法是 createNormalCaches()
// 参数一:normalCacheSize {64}
// 参数二:maxCachedBufferCapacity, 32k
// 参数三:directArena
// 创建出长度为 3的 MemoryRegionCache数组, 并且数组中每一个元素都是 NormalMemoryRegionCache类型
// 每一个 NormalMemoryRegionCache都会有一个固定长度的 queue(org.jctools包下的)- 这里是 64
normalDirectCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, directArena);
// 自增当前 directArena内共享的线程数目(PoolThreadCache占用 Arena, 前者每个线程独占)
directArena.numThreadCaches.getAndIncrement();
} else {
// No directArea is configured so just null out all caches
tinySubPageDirectCaches = null;
smallSubPageDirectCaches = null;
normalDirectCaches = null;
numShiftsNormalDirect = -1;
}
// 条件一般都会成立
// 这块逻辑和 directArena一样, 类比即可
if (heapArena != null) {
// Create the caches for the heap allocations
tinySubPageHeapCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
smallSubPageHeapCaches = createSubPageCaches(
smallCacheSize, heapArena.numSmallSubpagePools, SizeClass.Small);
numShiftsNormalHeap = log2(heapArena.pageSize);
normalHeapCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, heapArena);
heapArena.numThreadCaches.getAndIncrement();
} else {
// No heapArea is configured so just null out all caches
tinySubPageHeapCaches = null;
smallSubPageHeapCaches = null;
normalHeapCaches = null;
numShiftsNormalHeap = -1;
}
// Only check if there are caches in use.
if ((tinySubPageDirectCaches != null || smallSubPageDirectCaches != null || normalDirectCaches != null
|| tinySubPageHeapCaches != null || smallSubPageHeapCaches != null || normalHeapCaches != null)
&& freeSweepAllocationThreshold < 1) {
throw new IllegalArgumentException("freeSweepAllocationThreshold: "
+ freeSweepAllocationThreshold + " (expected: > 0)");
}
}代码块中先去保存了分配给当前线程的 heapArena以及 directArena (这里分配的 Arena是关键点,后续将从着入手),之后会去自增 Arena内共享线程数
然后根据 heapArena、directArena不空的判断,去创建各自对应的三种规格类型的 SubPageCaches,这块我们从直接内存缓冲方面进行分析:
分别去创建了 tinySubpageDirectCaches、smallSubpageDirectCaches、normalSubpageDirectCahces
对应的便是分别去创建各自长度的 MemoryRegionCache,对于前两者而言,数组中每一个元素都是 SubpageMemoryRegionCache类型,对于后者而言,则是 NormalSubpageDirectCaches类型
先分析前面一种情况:createSubPageCaches()
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches, SizeClass sizeClass) {
if (cacheSize > 0 && numCaches > 0) {
// 创建出指定长度的 MemoryRegionCache数组长度 - tiny,32; small,4; normal,3;
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
// TODO: maybe use cacheSize / cache.length
// 参数一:能够存放的内存位置信息数目
// 参数二:指定类型
// 实例化类型:SubpageMemoryRegionCache
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass);
}
return cache;
} else {
return null;
}
}实例化类型为 SubPageMemoryRegionCache
/**
* Cache used for buffers which are backed by TINY or SMALL size.
*/
private static final class SubPageMemoryRegionCache<T> extends MemoryRegionCache<T> {
SubPageMemoryRegionCache(int size, SizeClass sizeClass) {
super(size, sizeClass);
} // 参数一:能够存放的内存位置信息数目
// 参数二:指定类型
MemoryRegionCache(int size, SizeClass sizeClass) {
// 规范化 size大小 - 2的次方倍
this.size = MathUtil.safeFindNextPositivePowerOfTwo(size);
// 创建出固定长度的队列 - 里头存储的是 Entry
queue = PlatformDependent.newFixedMpscQueue(this.size);
this.sizeClass = sizeClass;
}可以看到,这里根据参数以及规格类型的不同,创建出了各自长度的一个 MemoryRegionCache数组,对于 tiny而是长度为 32的数组,其蕴意便是 32种规格类型,其实也就是 16b,32b,....,496b;之后便是每个数组元素内部会有着一个队列 (org.jctools包下的),队列长度为 512
对于 small类型则是去创建了长度为 4 (对应着 4种规格类型,其实就是 512b,1024b,2048b,4096b)的 MemoryRegionCache数组,每个元素内部的队列长度为 256
接着我们分析 Normal类型的 SubpageDirectCaches的创建,对应的便是:createNormalCaches()
// 参数一:normalCacheSize {64}
// 参数二:maxCachedBufferCapacity, 32k
// 参数三:directArena
private static <T> MemoryRegionCache<T>[] createNormalCaches(
int cacheSize, int maxCachedBufferCapacity, PoolArena<T> area) {
// true
if (cacheSize > 0 && maxCachedBufferCapacity > 0) {
// 由于 min(16mb, 32k), 因此这里的 max会是 32k
int max = Math.min(area.chunkSize, maxCachedBufferCapacity);
// arraySize -> 3
int arraySize = Math.max(1, log2(max / area.pageSize) + 1);
// 创建出长度为 3的 MemoryRegionCache数组 - 每个元素是 NormalMemoryRegionCache类型
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[arraySize];
for (int i = 0; i < cache.length; i++) {
// 参数:64, 每个元素能够去存储 64个内存位置信息(Normal类型)
cache[i] = new NormalMemoryRegionCache<T>(cacheSize);
}
return cache;
} else {
return null;
}
}可以看到,这里创建了长度为 3 (对应着 8k,16k,32k)的 MemoryRegionCache数组,实例化类型为 NormalMemoryRegionCache,其里头 queue长度为 64
至此,与线程相关的本地缓存获取完毕
基于 directArena进行内存分配
接着回到主逻辑:
// 参数一:指定想要去分配的内存
// 参数二:允许分配的最大内存:Integer.MAX_VALUE
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 每个线程都会去 threadCache(PoolThreadLocalCache类型, 继承自FastThreadCache)中去获取线程相关的 PoolThreadCache(起到延迟释放 ByteBuf的作用)
// 这里便是去获取 | 创建线程独占的 PoolThreadCache, 并进行相应的初始化操作
// 每个 PoolThreadCache中会有两个区域:HeapArena、DirectArena
PoolThreadCache cache = threadCache.get();
// 获取分配给当前线程的 directArena区域, 后面会在这个区域进行内存的申请操作
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
// true
if (directArena != null) {
// 参数一:当前线程相关的 PoolThreadCache
// 参数二:指定想要去分配的内存容量
// 参数三:允许分配的最大内存:Integer.MAX_VALUE
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}我们考虑的仍然是基于直接内存的分配方式,其实底层实际上就是通过 directArena去进行内存的分配
先去调用了 directArena.allocate()
// 参数一:当前线程相关的 PoolThreadCache
// 参数二:指定想要去分配的内存容量
// 参数三:允许分配的最大内存:Integer.MAX_VALUE
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// 获取一个 ByteBuf对象, 在这一步时该 byteBuf还未去管理任何内存, 其作为一个内存容器
PooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 参数一:当前线程相关的 PoolThreadCache
// 参数二:上一步获取的一个内存容器, 下面逻辑会给 buf去分配真正的内存
// 参数三:指定想要去分配的内存容量
// 核心逻辑
allocate(cache, buf, reqCapacity);
return buf;
}在这里先去调用了方法 newByteBuf(),参数传递的是 Integer.MAX_VALUE
获取内存容器
DirectArena.newByteBuf()
@Override
protected PooledByteBuf<ByteBuffer> newByteBuf(int maxCapacity) {
// 一般情况下, 这里会是 true
if (HAS_UNSAFE) {
return PooledUnsafeDirectByteBuf.newInstance(maxCapacity);
} else {
return PooledDirectByteBuf.newInstance(maxCapacity);
}
}
static PooledUnsafeDirectByteBuf newInstance(int maxCapacity) {
// 从对象池中获取一个空闲状态的 ByteBuf对象, 如果没有空闲的 ByteBuf则去创建
PooledUnsafeDirectByteBuf buf = RECYCLER.get();
// 重置 buf内一些字段, 设置 maxCapacity为参数值
buf.reuse(maxCapacity);
// 返回
return buf;
}而 RECYCLE是类 PooledUnsafeDirectBytebuf中全局的一个对象池:
final class PooledUnsafeDirectByteBuf extends PooledByteBuf<ByteBuffer> {
// 这是一个全局的对象池 - 这便是直接内存的池化的体现
private static final ObjectPool<PooledUnsafeDirectByteBuf> RECYCLER = ObjectPool.newPool(
new ObjectCreator<PooledUnsafeDirectByteBuf>() {
@Override
public PooledUnsafeDirectByteBuf newObject(Handle<PooledUnsafeDirectByteBuf> handle) {
return new PooledUnsafeDirectByteBuf(handle, 0);
}
});我们所考虑的是 directArena,因此这里便是 Netty中池化的直接内存的体现
这里通过 RECYCLE去获取了一个处于空闲状态的 ByteBuf对象,如果没有空闲的 ByteBuf则去创建
之后就是进行一些 reset操作:
/**
* Method must be called before reuse this {@link PooledByteBufAllocator}
*/
final void reuse(int maxCapacity) {
// 设置当前 buf可写的最大容量
maxCapacity(maxCapacity);
resetRefCnt();
setIndex0(0, 0);
discardMarks();
}由于参数传递的 Integer.MAX_VALUE,因此这里去获取的 ByteBuf其实并不是我们业务层面指定容量的 ByteBuf
也就是说,在 newByteBuf()中,在这一步获取的 byteBuf本身并未去管理任何内存,现在只是作为一个内存容器而已
接下来,便是去进行指定内存容量的分配操作,对应的便是 allocate()方法
对内存容器进行内存的分配
第一次进行内存分配时,由于与线程相关的 PoolThreadCache中还未去存放任何内存,因此会去到 Arena中去进行内存的分配,因为 Arena是 Allocator管理着的,并且是多线程间共享着的嘛
我们考虑的仍然是 directArena的情况,回到主逻辑,对应的便是 directArena.allocate()
// 参数一:当前线程相关的 PoolThreadCache
// 参数二:上一步获取的一个内存容器, 下面逻辑会给 buf去分配真正的内存
// 参数三:指定想要去分配的内存容量
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 将业务请求分配的内存容量转换为一个符合规格的容量()
final int normCapacity = normalizeCapacity(reqCapacity);
// CASE1:转换出来的 规格 size是 tiny | small类型
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
// Arena内有两个数组:tinySubpagePools、smallSubpagePools, 会根据 normCapacity计算出合适的下标位置
int tableIdx;
// 最终会指向 tinySubpagePools、smallSubpagePools中一个
PoolSubpage<T>[] table;
// 计算当前规格 size是不是 tiny类型
boolean tiny = isTiny(normCapacity);
// Tiny类型
if (tiny) { // < 512
// 先不考虑从线程本地缓存中分配内存, 假设这一步申请失败, 等后面解读完释放内存后再来看
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
// 根据 规格 size计算出在 tinySubpagePools数组中合适的一个下标
// 假设 normCapacity == 48
// 这里获取的便是 3, 便是数组下标第三个位置
tableIdx = tinyIdx(normCapacity);
// 选择 tinySubpagePools数组
table = tinySubpagePools;
} else { // small类型
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
// 根据 规格 size计算出在 smallSubpagePools数组中合适的一个下标
// 假设 normCapacity == 2048
// 这里获取的便是 3, 便是数组下标第三个位置
tableIdx = smallIdx(normCapacity);
// 选择 smallSubpagePools数组
table = smallSubpagePools;
}
// 上面不管是 tiny还是 small, table、tableIdx都已经计算完毕
// 这里会获取到对应 table中对应桶位处的 head节点 - 在数组初始化时每个桶位处都会有一个 head节点(初始化时 head的 prev、next都指向自身)
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
// 将 head节点作为锁
synchronized (head) {
// 初始化时 head的 prev、next都指向自身
// 只有 Arena内申请过某个规格的 subpage后, 对应的下标桶内才会有 page
final PoolSubpage<T> s = head.next;
// 条件成立:说明该规格的桶位有 subpage了, 先不来考虑这种情况
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
// 锁住当前 Arena
synchronized (this) {
// 最为复杂的逻辑... Arena的 subpagePools和线程的本地缓存 PoolThreadCache都没能满足内存的分配, 则会走 allocateNormal逻辑
// 参数一:上一步获取的一个内存容器, 下面逻辑会给 buf去分配真正的内存
// 参数二:指定想要去分配的内存容量
// 参数三:规格化后的 size
allocateNormal(buf, reqCapacity, normCapacity);
}
incTinySmallAllocation(tiny);
return;
}
// CASE2:转换出来的 规格 size是 normal类型, 8k, 16k, 32k.... 但小于等于 16mb
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
}
// CASE3:转换出来的 规格 size是 Huge类型, 超大规格 > 16mb
else {
// Huge allocations are never served via the cache so just call allocateHuge
// 这种超大规格内存的分配, 是不会去走池内内存分配, 而是由 os向池外进行分配
allocateHuge(buf, reqCapacity);
}
}代码虽长,但主逻辑清晰明了
规格化 size
首先便是去规格化业务请求分配的内存容量,对应的是 normalizeCapacity()
// 参数:reqCapacity 用户请求分配的内存容量 - 这是一个随意的值
// 将业务请求分配的内存容量转换为一个符合规格的容量 - 其实也就是 "预定义好的"一个规格大小
int normalizeCapacity(int reqCapacity) {
checkPositiveOrZero(reqCapacity, "reqCapacity");
// 条件成立 - 用户请求超大容量内存的分配 > 16mb, 如果是这种情况的话, 则会去进行超大内存的分配
if (reqCapacity >= chunkSize) {
return directMemoryCacheAlignment == 0 ? reqCapacity : alignCapacity(reqCapacity);
}
// 条件成立, 用户请求分配容量大于等于 512b
// 这里实际上就是去排除 Tiny类型的容量分配
if (!isTiny(reqCapacity)) { // >= 512
// Doubled
// 来到这, 只有两种规格了:Small、Normal
// 为了便于理解, 这里假设一种情况:reqCapacity == 555
int normalizedCapacity = reqCapacity;
// 554 - 0b 0000 0000 0000 0000 0000 0010 0010 1010
normalizedCapacity --;
// 接下来的算法其实在 HashMap时已经讲过了的...
/**
* 0b 0000 0000 0000 0000 0000 0010 0010 1010
* |
* 0b 0000 0000 0000 0000 0000 0001 0001 0101
* -> 0b 0000 0000 0000 0000 0000 0011 0011 1111
*/
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
// 1023
normalizedCapacity |= normalizedCapacity >>> 16;
// 1024
normalizedCapacity ++;
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
assert directMemoryCacheAlignment == 0 || (normalizedCapacity & directMemoryCacheAlignmentMask) == 0;
// 经过上面的算法后, 得到的数会是一个大于等于 reqcapacity的最小二次方的一个数
return normalizedCapacity;
}
// 来到这, 便是 tiny类型的内存分配的请求 < 512b
if (directMemoryCacheAlignment > 0) {
return alignCapacity(reqCapacity);
}
// Quantum-spaced
// 判断 reqCapacity是不是这些规格:16, 32, ..., 496(由上述知, 来到这只会是 <= 512)
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
// 来到这, 说明数值可能是 17, 33, 45之类的值
// 这里来做了些转换
// 这里实际返回的便是大于等于当前值的是 16的倍数的一个数(小于等于 496)
return (reqCapacity & ~15) + 16;
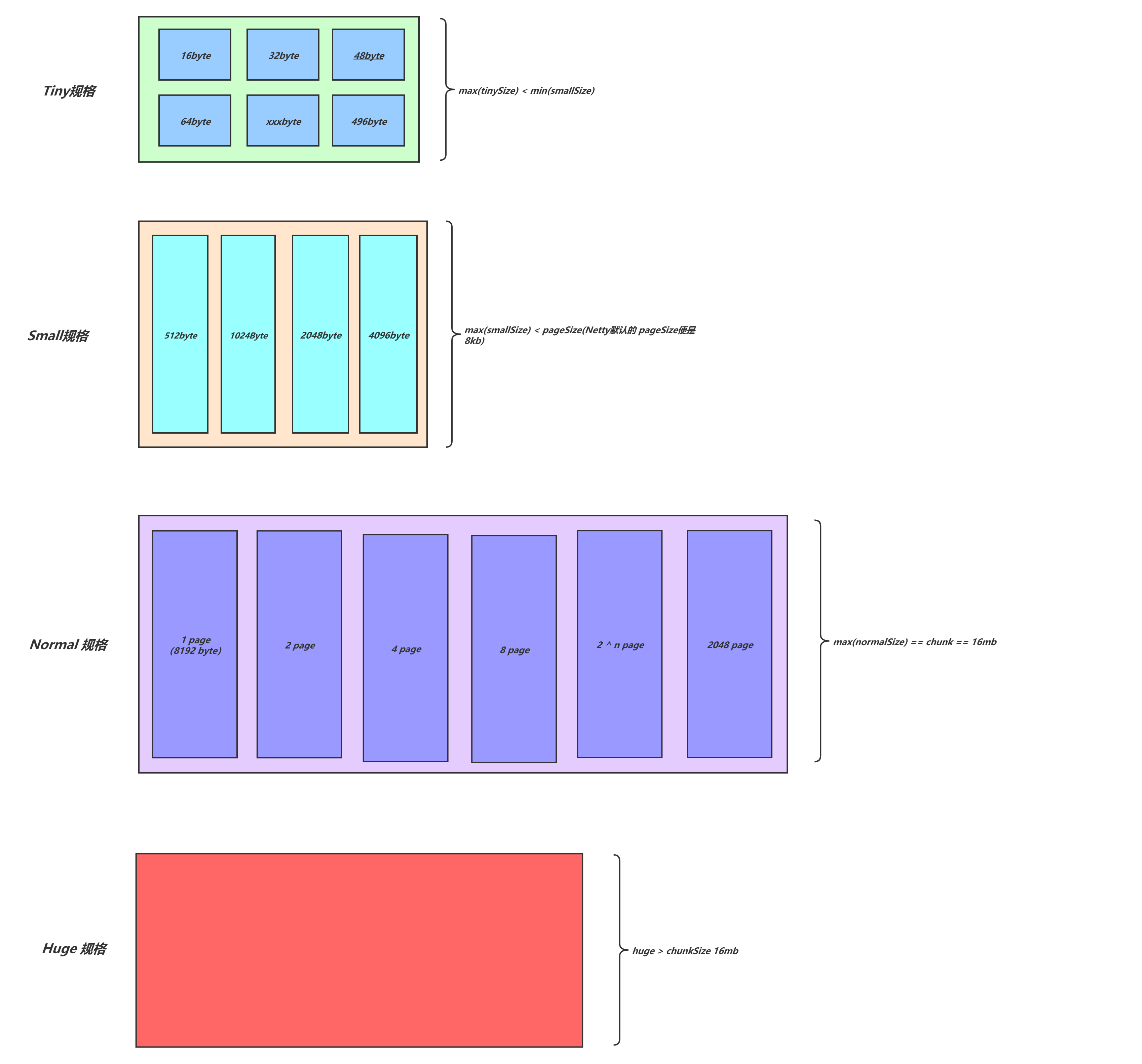
}将业务请求分配的内存容量大小转化为符合规格的 size,这说明每次分配对应的都是某个规格化的 size (即,预定义好了的规格大小),而不是随心想要多少就给你多少,是经过规格化管理的,这其实也是便是规格类型的分化管理
从上可以看出,对应 tiny类型规格,对应的便是:16b,32b,...,496b,共 31种规格
对于 small类型规格,对应:512b,1024b,2048b,4096b,共四种规格
对于 normal类型规格,对应 8k,16k,24k,...,16mb (这里是小于等于 16mb)
对于大于等于 16mb的请求内存容量,这里判断出来后会直接返回,这里对应的其实是 huge类型规格,从这可以猜想,对于 Huge大规格内存容量请求分配,还是经由池化内存分配的吗?这里留一个疑点!
继续回到主逻辑
尝试一之本地缓存分配
接着,会去判断规格化的 size是哪一种类型,对应三种 CASE:isTinyOrSmall、normCapacity <= chunkSize、以及 Huge类型
先来看第一种情况:
显示区判断了规格化的 size是不是 tiny 或 small类型,对应:
// capacity < pageSize
boolean isTinyOrSmall(int normCapacity) {
return (normCapacity & subpageOverflowMask) == 0;
}接着,会细分是 tiny还是 small类型的规格,判断出来后,先尝试去与当前线程相关的 PoolThreadCache中去分配内存,这里对应的 cache也正是前面所获取的 cache,我们假设程序第一次执行到这,显然这块向 PoolThreadCache申请内存的逻辑会失败,因为这块内部还未管理任何内存,对应的便是还没有内存释放存进去,这里是个关键点
从线程相关的本地缓存申请内存失败后,接着又该怎么办?
尝试二之 Arena中 subpagePools进行分配
接着其实是会去尝试到 Arena中去申请内存,前面讲过,每个线程都被分配了一个 heap类型的 Arena以及 direct类型的 Arena
这里对应的便是两个字段:table、tableIdx
前者表示规格化的 size对应的是 Arena中哪个 subpagePools数组,前面分析过,Arena中存在两种类型的 subpagePools,即 TinySubpagePools、smallSubpages,前者长度 32,实际上只有 31种规格,后者长度为 4,对应的便是 4中规格
后者表示的便是通过规格化后的 size计算出的在对应 table中的指定下标
这里先来分析 tiny类型,对应 tinyIdx(normCapacity):
// 假设 normCapacity == 48
// 这里获取的便是 3, 便是数组下标第四个位置(数组下标为 0实际上只会去存储 head节点)
static int tinyIdx(int normCapacity) {
// 0b 11 0000 -> 0b 00 0011 -> 3
return normCapacity >>> 4;
}接着便是 smallIdx(normCapacity):
// 假设 normCapacity == 2048
// 这里获取的便是 2
static int smallIdx(int normCapacity) {
int tableIdx = 0;
// 0b 1000 0000 0000 >>> 10
// 0b 0000 0000 0010 - 2
int i = normCapacity >>> 10;
while (i != 0) {
i >>>= 1;
tableIdx ++;
}
// 这里计算出来的便是 2
return tableIdx;
}这块便计算出了规格化后的 size在对应 table中的对应下标值
继续回到主逻辑
接着便是获取到对应桶位的 head节点:
// 上面不管是 tiny还是 small, table、tableIdx都已经计算完毕
// 这里会获取到对应 table中对应桶位处的 head节点 - 在数组初始化时每个桶位处都会有一个 head节点(初始化时 head的 prev、next都指向自身)
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
// 将 head节点作为锁
synchronized (head) {可以看到,SubpagePools中 head节点并不具备分配内存的能力,其存在的意义是作为 "锁"
接着便是去判断 head的后继节点等不等于 head
而在前面初始化时分析过,SubpagePools初始化时每个桶位都存进去了一个 head节点,而这个 head节点的 prev、next都会指向自己
这块进行判断,主要是判断 head所在桶位是否存储过指定规格 (也是当前预分配的规格) size,是的话,那么 head.next节点就不会再指向 head自身了,而是对应的 PoolSubpage节点
咋们仍然假设程序试一次执行到这,因此,这块条件判断不成立
来到这,已经尝试进行两次快捷内存的分配了:先尝试从与线程相关的本地缓存中去申请内存,失败了,再尝试到分配给当前线程的 Arena中的对应 subpagePools中申请内存,这也失败了
接下来该怎么办呢?














不错