
随笔分类
RDB
Redis DataBase
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是Snapshot快照,它恢复时直接将快照内存里
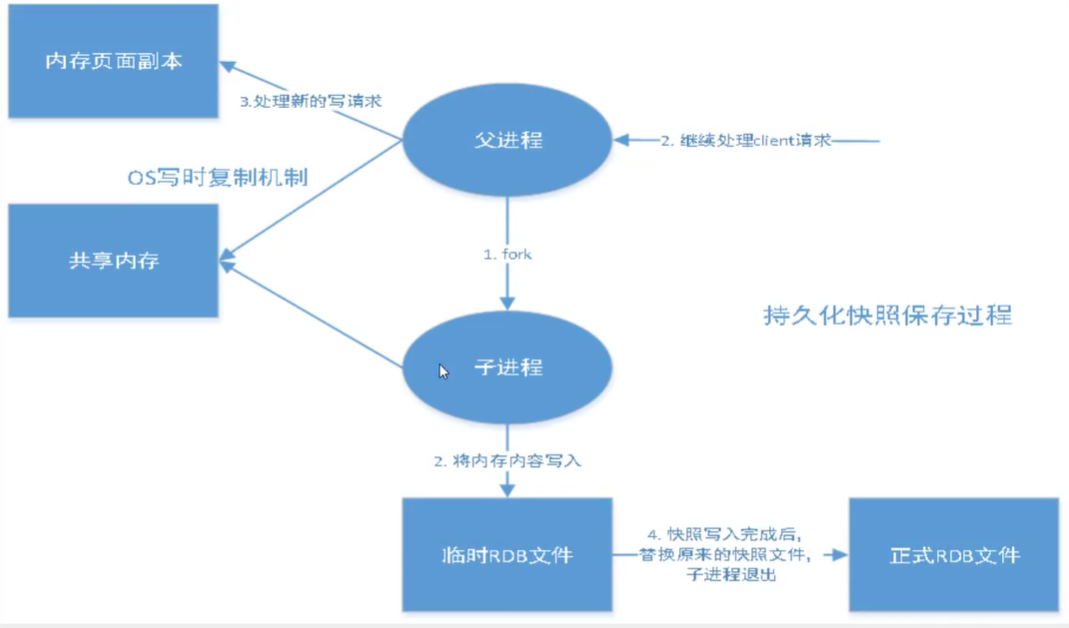
Redis会单独创建(folk)一个子进程来进行持久化,会现将数据写入一个临时RDB文件中,待持久化过程都结束后,再用这个持久化文件替换上次持久化好的文件,即此时该临时的持久化文件便转正了
整个过程中,主进程是不进行任何IO操作的,这就得到了极高的性能.
在主从复制中,rdb就是备用的,放在从机上面
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那么RDB方式要比AOF方式更加的高效
RDB的缺点:最后一次持久化的数据可能会丢失(刚好出现宕机).
默认便是RDB持久化,一般情况下不需要修改这个配置
rdb默认持久化的文件名:dump.rdb

在生产环境中,常需要将rdb文件进行备份
测试
修改redis.conf
# save 900 1
# save 300 10
# save 60 10000
save 60 5 //只要60s内修改了五次及其以上,就会进行持久化的操作被动触发机制
- 满足save规则便会触发持久化机制
- flushALL(注意:flushdb不会)命令会触发持久化机制
- 关闭redis进程也会触发持久化机制
手动触发机制
两种方法
-
1)save
同步操作,会阻塞当前的Redis服务器,执行save命令期间,Redis不能处理其他命令,知道RDB过程完成
-
2)bgsave
Background saving
异步操作,Redis主线程 fork出一个新进程,原来的Redis主线程去处理客户端请求,而子进程负责将数据(即快照)保存到临时的RDB文件中,待持久化结束后替换掉原来的RDB文件即可,然后退出
127.0.0.1:6379> bgsave Background saving started 127.0.0.1:6379> lastsave (integer) 1605627555 127.0.0.1:6379>显然 bgsave更加适合RDB操作,所以RDB的内部操作以及自动触发等,也是 bgsave
RDB bgsave具体流程:
- Redis服务器接收到 bgsave,主线程需要调用系统的 fork()函数去创建一个子进程进行操作
- 子进程创建到RDB文件并退出时,像父进程发送一个通知信号,告知RDB文件创建完毕
- 父进程接收子进程创建好的RDB文件,bgsave命令结束
- Redis服务器在 bgsave执行期间仍然可以继续处理客户端的请求
恢复快照
-
只需要将rdb文件放在redis启动目录即可,redis启动的时候回自动检查dump.rdb 并且来恢复数据库内存的数据
-
查看redis的启动目录
127.0.0.1:6379> config get dir 1) "dir" 2) "/usr/local/redis/bin" 127.0.0.1:6379>优点
- 适合大规模数据的恢复
- 对数据的完整性不高
缺点
- 需要一定的时间间隔来进行持久化!如果在此期间意外发生了宕机,那么最后一次进行修改的数据就没了
- fork进程的时候,会占用一定的内存空间













