随笔分类
SDS

Strings
Redis在实现时选择并没有去选择传统的C字符串
而是选择了 SDS
Simple Dynamic String
在Redis里C字符串只会作为一个字符串字面量,多用于一些无需对字符串进行修改的地方,比如打印日志等
但是Redis需要的并不仅仅是一个字面量的字符串,而是一个可以被修改值的字符串,这时候便用上了 SDS
redis> SET msg "hello world"
# 此时键值都是字符串对象,对象的底层实现实际上是一个保存了字符串 "msg" 和 "hello world"的SDSSDS还可以用来做缓冲区
SDS结构

- int free:记录buf已分配的未使用空间
- int len:记录buf数组中已经使用字节的数量 -> 即SDS中所保存字符串的长度
- char[] buf:字节数组,用来保存字符串(Redis不是用这个数组来保存字符的,而是用来保存一系列的二进制数据的)
SDS和C字符串结尾保存规则一致,都是以'\0'结尾,这样的话SDS就可以直接重用一部分C字符串函数库里面的函数
注意:结尾的空字符是对SDS的使用者完全透明的,其1字节的分配以及添加到字符串末尾的操作都是有SDS API来完成,SDS的使用者无需来关心这一步如何来实现
SDS 与 C字符串的区别
对于C字符串:字符串长度和底层数组是紧密联系着的,这也就意味着每次字符串长度的变化都会触发一次内存重分配策略
内存重分配涉及复杂的算法,并且可能需要执行系统调用,其实一个比较耗时的操作
Redis难以容忍这个时间消耗
而SDS中通过free字段解耦了字符串长度和底层数组长度的关联
SDS实现的两种优化策略
-
空间预分配
用于优化SDS字符串的
增长操作,当 SDS的API对一个SDS进行修改,并且需要对SDS空间进行扩展时,程序不仅需要为SDS分配修改所必须的空间,还会为其分配额外的未使用空间规则
- 如果对SDS进行修改后,SDS长度(len)小于1MB的话,那么程序将分配和len属性同样大小的未使用空间
- 如果对SDS进行修改后,SDS长度(len)大于等于1MB的话,那么程序会分配1MB的未使用空间
通过这种策略,能有效减少连续执行多次字符串增长操作所需的内存重分配次数
-
惰性空间释放
用于优化SDS字符串的
缩短操作当SDS的API需要缩短SDS保存的字符串时,并不立即使用内存重分配来回收缩短之后多出来的字节,而是将其数目记录在free里,并且等待将来的使用
即SDS避免了字符串缩短是所需的内存重分配操作,并且为将来可能有的增长操作提供了优化
SDS也提供了一些API,可以在有需要的时候,真正的释放SDS的未使用空间,所以不用去担心惰性空间释放造成内存的浪费
如图:
| C字符串 | SDS |
|---|---|
| 获取字符串的长度的复杂度为O(N) | 获取字符串的长度的复杂度为O(1) |
| API是不安全的,可能会造成缓冲区的溢出(strcat函数使用前需手动实现所需的扩展空间分配,不然可能会覆盖相邻存储着的字符串的值) | API是安全的,不会造成缓冲区的溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | SDS API是二进制安全的,以二进制的方式来处理buf字节数组里保存的数据,不会对其中的数据进行任何限制、过滤,即数据保存在里面时是什么样的,取出来也是什么样的 |
| 可以使用所有 |
可以来使用一部分 |
链表
列表键底层实现之一
C语言并没有内置此数据结构,Redis构建了自己的链表实现.
当一个列表键包含了数量比较多的数量,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表做为链表键的底层实现.
除了链表键之外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息.
结构
双端链表
每个链表节点用listNode结构来表示
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
//节点的值 --> 实现多态
void *value;
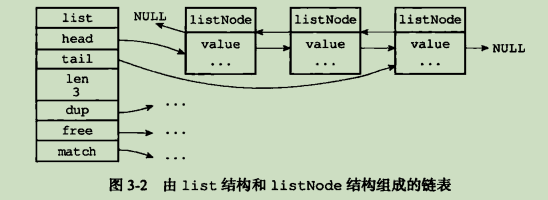
} listNode多个listNode通过prev和next指针组成双端链表

虽然仅仅使用listNode结构就可以组成链表,但使用list来持有链表的话,操作起来会更加方便:
typedef struct list {
// 表头节点
listNode *head;
// 表尾结点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void *(*free)(void *ptr);
// 节点值对比函数
void *(*free)(void *ptr, void *key);
} listdup、free、match成员是用于实现多态链表所需的类型特定函数.
特性
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1).
- 无环:表头节点和prev指针和表尾结点的next指针都指向NULL,对链表的访问以NULL为终点
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾结点的复杂度为O(1).
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1).
- 多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free、match三个属性作为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值.
字典
dict
又称符号表(symbol table)、关联数组(association array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构
在字典中,一个键(key)可以和一个值(value)进行关联(或者说将键映射为值).
Redis使用的C语言并没有内置这种数据结构,因此Redis构建了自己的字典实现.
字典在Redis中的应用相当广泛,比如Redis的数据库就是使用字典来作为底层实现,对数据库的增、删、改、查操作也是构建在对字典的操作之上.
哈希键底层实现之一
当一个哈希键<key, <key, value>>包含的键值对比较多时,又或者键值对中的元素都是比较长的字符串时,Redis就会使用字典作为哈希键的底层实现.
实现
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对.
哈希表
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表子网掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht哈希节点
table属性是一个数组,数组中每一个元素都是一个指向dictEntry结构的指针,每个dictEntry结构保存着一个键值对
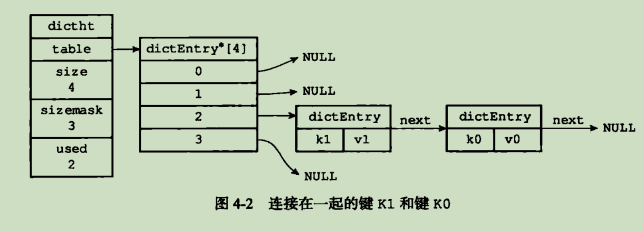
typedef struct dictEntry {
// 键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v
// 指向下个哈希表节点,形成链表
// 可将多个哈希值相同的键值对连接在一起,以来解决键冲突(collision)的问题
struct dictEntry *next;
} dictEntry;字典
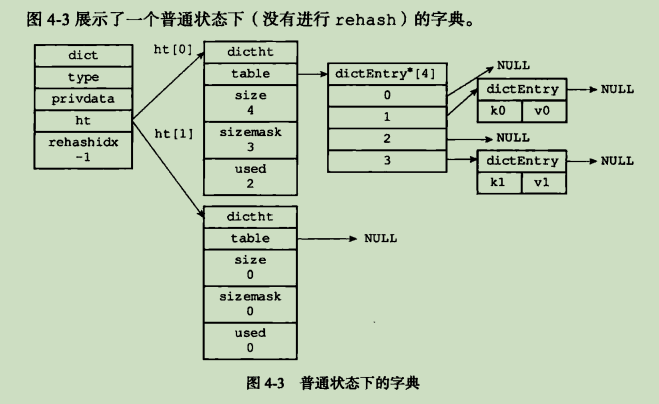
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
// 一般情况下,字典只使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用.
dictht ht[2];
// rehash索引
// 当rehash不再进行时,值为-1
// 记录的是rehash的进度
in trehashidx;
}type属性和privdata属性是针对不同类型的键值对,为创建多态字典而设置的
- type属性是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特定函数
- 而privdata属性则保存了需要传给那些类型特定函数的可选参数
哈希算法
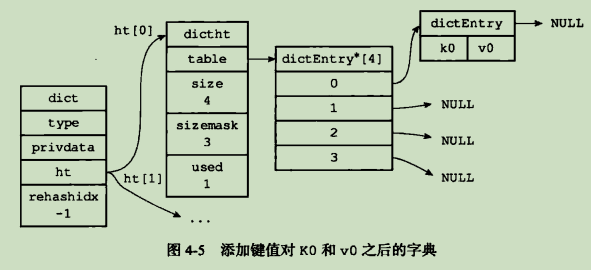
当要将一个新的键值对添加到字典里面时,程序需要先根据键值对的键计算出哈希值和索引值,然后根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面.
// Redis计算哈希值
// 使用哈希表的sizemask属性和哈希值,计算出索引值
hash = dict->type->hashFunction(key)
// Redis计算索引值
// 此算法可以得到均匀的索引值,Magic index,即随机分布性好
index = hash & dict->ht[x].sizemask; 解决键冲突
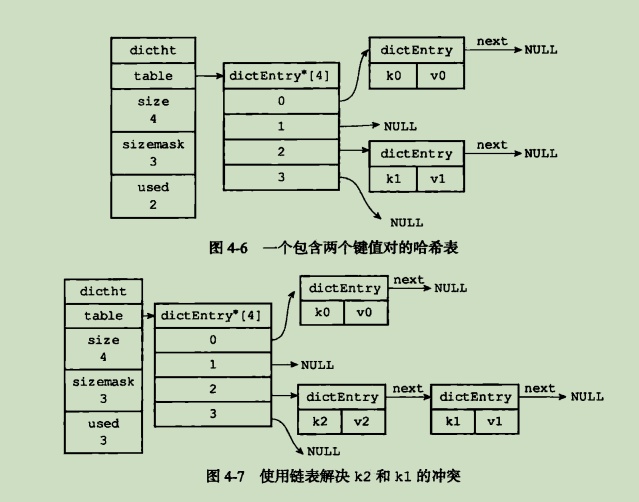
Redis使用链地址法(separate chaining)来解决键冲突,每一个哈希表结点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这便解决了键冲突的问题.
dictEntry节点组成的链表没有指向链表尾部的指针,因此为了速度考虑,程序总是将新节点添加到链表的表头位置(复杂度O(1)),排在其他已有节点的前面.
rehash
重新散列
重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(load factor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩.
扩展和收缩哈希表的工作可以通过执行rehash(重新散列)操作来完成,Redis对字典的哈希表执行rehash的步骤如下:
- 为字典的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(也即使ht[0].used属性的值):
- 如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].used*2的2^n;
- 执行收缩操作,那么ht[1]的大小为第一个对等于ht[0].used的2^n;
- 将要保存在ht[0]中的所有键值对rehash到ht[1]上面
- 当ht[0]包含的所有键值对都迁移到ht[1]之后(ht[0]变为空表),释放掉ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备.
哈希表的扩展与收缩
当以下条件中任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有执行
BGSAVE命令或者BGREWRITINGAOF命令,并且哈希表的负载因子大于等于1 - 服务器目前正在执行
BGSAVE命令或者BGREWRITINGAOF命令,并且哈希表的负载因子大于等于5
负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].size根据BGSAVE或BGREWRITINGAOF命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行BGSAVE命令或BGREWRITINGAOF命令的过程中,Redis需要创建当前服务器的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能减少子进程存在期间进行哈希表的扩展操作,这可以避免不必要的写入操作,最大限度地节省内存.
另一方面,当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作
渐进式rehash
避免rehash(过大的计算量)对服务器性能造成影响
rehash动作并非一次性、集中式地完成的,而是分多次、渐进式地完成的
步骤
- 为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
- 在字典中维持一个
索引计数器变量rehashidx,并将其值设为0,表示rehash工作正式开始 - 在rehash进行期间,
每次对字典执行crud时,程序除了执行执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一. - 随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性值设为-1,表示rehash操作已完成
渐进式的rehash的害处在于其采取了分而治之的方式,将rahash键值对所需的计算工作均摊到对字典的增加、删除、查找和更新操作上,从而避免了集中式rehash而带来的庞大计算量.
渐进式rehash执行期间的哈希表操作
因为在进行渐进式rehash的过程中,字典会同时使用ht [0]和ht[1]两个哈希表,所以在渐进式rehash进行期间,字典的删除( delete)、查找(find)、更新( update)等操作会在两个哈希表上进行. 例如,要在字典里面查找一个键的话,程序会先在ht[0]里面进行查找,如果没找到的话,就会继续到ht[1〕里面进行查找,诸如此类.
另外,在渐进式rehash执行期间,新添加到字典的键值对一律会被保存到ht[1]里面,而ht[0]则不再进行任何添加操作,这一措施保证了ht[0]包含的键值对数量会只减不增,并随着rehash 操作的执行而最终变成空表












