
随笔分类
Buffer Pool Optimizations
针对 Buffer Pool的优化
Multipart Buffer Pool
多缓冲池
实际上我们可以有多个缓冲池,即分配多个内存区域,每个内存区域对应着一个 Page Table,各自管理着一套 page id和 frame的映射关系
这有什么好处 --> 分配多个缓冲池
-
分配多个缓冲池,这有益于我们对单个缓存池区域进行局部策略的优化
-
而且能够减少那些访问 Buffer池的不同线程间争抢 Latch的情况发生
当我们去读取数据时,找到 Page Table中对应数据所在 frame的 映射那一项,此时会在 table中对应项加上 Latch,以来 保证在读取到对应页中数据的期间,对应的 page不会被置换出去
能有效减少同一时刻 Latch的争用,以来提高局部性
在多个缓冲池下,给定一个 page id,如何来确定其在哪个缓冲池中的哪个 frame中?
通常有两种方式:
-
维护数据库对象的 id
Buffer池通过将数据库对象的 record id维护管理起来,以此来管理数据库对象 (database object)
通过将数据库对象的 record id维护到一个列表中,这样就能根据每个 id找到对应的对象条目
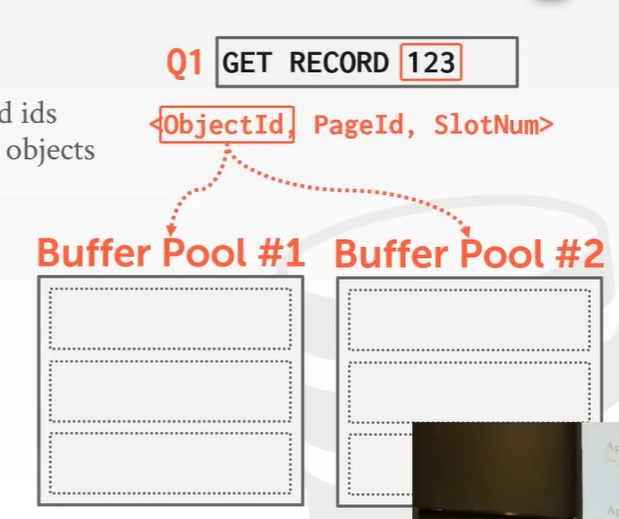
当有上层请求拿某个 record id时,通过解析请求,找到 record id对应的 Buffer Pool中所对应的 Page id
-
使用 Hash
这也是 MySQL中所选择的做法
传入一个 record id,对其进行 hash以来确定 Buffer池的位置,并且使用 record id对使用的 Buffe数量 n进行取模,依赖确定数据库对象在那个缓存池里
Pre-Feching
预取
DBMS可以 根据查询计划来预取页面,这样能够最小化随机 IO带来的影响
-
线程读取内存中不存在 page时,此时需要阻塞等待 从磁盘中 读取 page
page的读取实际上是会从上一次 page的位置进行读取的
当我们要进行 顺序扫描时,可以通过来预读取 page,依赖减少磁盘 IO的次数
- 一次读取 n个相连的 page,好过一个一个的分开进行读取(不进行预读,发现 page不在内存中时,便会这样来做)
通过预读,能够减少停顿产生的影响,而这些停顿也就是从磁盘中读取数据所带来的
还有一种方式时通过 索引扫描
对 page进行了索引
当有这么一条 query时:

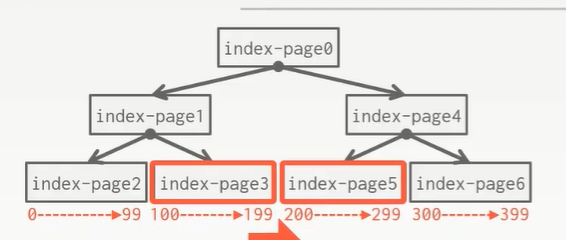
通过索引得到,我们想要读取的 page是 page3和 page 5,但在磁盘上它们可能不是连续的 page
对于 os可能就会将相连着的 page2和 page3读进内存,这显然不是我们想要的结果
对于 DBSM而言,很清楚地知道 page中存有的数据以及本次查询要干的事
可以通过额外保存一些元信息的方式(比如:page3清楚知道其兄弟节点 page5所在磁盘上的位置),再读取时也能够去预读取 page3、page5读进 Buffer Pool中去
-
对于数据库而言,很清楚地知道本次查询要做的事情,能够很好地来进行预取
对于 OS而言,mmap便不能很好地做到这一点
Scan Sharing
扫描共享
基本思想:复用某个查询从磁盘中读取到的数据,将该数据用于其他查询
- 区别于 结果缓存(Result Buffer):结果缓存在存储器层面进行,只能是针对于相同的查询,以此来避免重新来执行一次 query
可以横跨不同的线程来共享这些即时结果
工作方式:允许多个查询附加到单个游标上时(将这些查询注册到这个游标数据结构管理的一个集合中),扫描我们的 pages,并将它们放入到 Buffer池中去
- 查询不一定是一样的
- 可以来分享中间结果
经过分析执行计划得知,前后查询之间存在共同 page的读取,先 将后一次查询的游标附加在前一次查询中去(需要跟踪后一个查询出现的位置,并搭上前一个查询的顺风车),记录位置后,拿到数据后可以返回(返回的可以是前一个查询,也可以是后一个查询),然后继续来走原来的剩余逻辑
- 此时后一个查询可能存在中间结果值的记录,这些记录会存放于内存中,但因为这些数据是短暂的内存数据,因此也可以来根据 Buffer池的实现来存储中间结果值(可以 LRU)
- 当有查询在磁盘 IO时,别的线程可以去访问 Buffer池中存在的数据(同一时间可能会有别的线程去读取这个数据),此时可以通过一些高层次的东西,例如 通过 locks对一些 pages进行跟踪管理是否允许对这些 pages进行读和写,或者是将 locks应用于你所知道的数据库对象上(database objects)
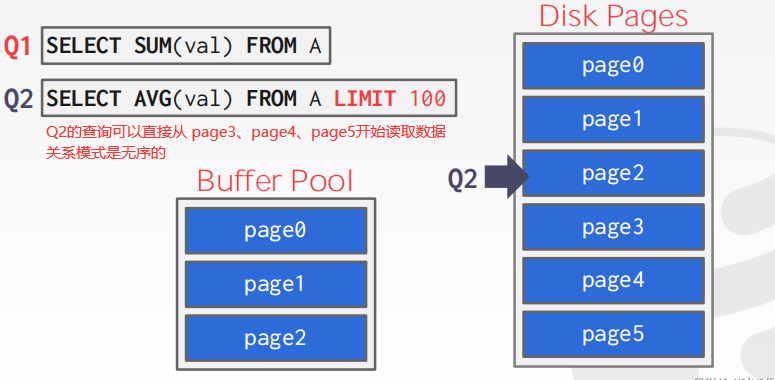
注意:关系模式是无序的(数据库是无序的),对应有些查询,只需要拿到结果即可,并不要求一定要从 page最初始处开始拿数据
Buffer Pool Bypass
也叫 Buffer Cache Bypass,取决于系统的实现
DBMS根据查询计划 (比如:线程进行顺序扫描时),有时会分配一小块内存给执行查询的那条线程,线程此时不会从 page table中去拿数据,它必须从磁盘中拿到 page,如果对于的 page在 Buffer Pool中不存在时,此时不会将它放入 buffer池中(避免缓存污染),而是将 page放入本地内存中,当查询结束时,pages便被丢失
- 这么做也是为了避免从 page table中进行查询而带来的开销 --> page table是 hash table,查询时需要对条目进行 Latch锁的,这部分开销不能忽略
- 操作的是中间结果值或者扫描量不大时,可以暂存于 bypass中
- 扫描量大时,此时就不得不用到 buffer池了,通过 refresh一部分数据以来大量最终的数据量













